摘要:从11月27日到12月9日,大概花了一个星期的时间,终于啃完了621页的《Linux命令行与shell脚本编程大全》。
文章说明
文章作者:鴻塵
文章说明:学习shell过程中的记录,参考书籍主要有《Linux命令行与shell脚本编程大全(第3版)》,《鸟哥的Linux私房菜(第三版)》系列和《快乐的 Linux 命令行》,参考资料主要有Linux命令大全等。
文章链接:https://hwame.top/20201127/learning-linux-shell-script.html
1.构建基本脚本
1.1.创建shell脚本文件
创建shell脚本文件时,必须在文件的第一行指定要使用的shell。其格式为:1
!/bin/bash
在指定了shell之后,就可以在文件的每一行中输入命令,然后加一个回车符。
在通常的shell脚本中,井号(#)用作注释行。shell不会解释以#开头的行(除了以#!开头的第一行)。
1.2.运行脚本
①作为可执行程序
首先需要具有执行权限:chmod +x ./myfile,然后在脚本所在目录输入./myfile执行脚本。
注意:若直接输入myfile则会报错「命令未找到」,因为shell会通过PATH环境变量来查找命令,所以可以采取两种方法:
- 将shell脚本文件所处的目录添加到
PATH环境变量中; - 用绝对或相对文件路径来引用shell脚本文件,如上使用相对路径。
②作为解释器参数
直接运行解释器,其参数就是shell脚本的文件名。例如/bin/sh myfile。注意,Linux下的可执行文件不需要拓展名,只需要拥有执行权限即可,因此文件名为myfile或myfile.sh都行。
2.使用结构化命令
2.1.使用if-then语句
最基本的结构化命令就是if-then语句。if-then语句有如下格式:1
2
3
4if command
then
commands
fi
注意:在其他编程语言中,if语句之后的对象是一个等式,这个等式的求值结果为TRUE或FALSE,条件为真时才执行then部分。bash shell的if语句会运行if后面的那个命令,如果该命令的退出状态码是0(即该命令成功运行),位于then部分的命令就会被执行。如果该命令的退出状态码是其他值,then部分的命令就不会被执行。
注意:再说一遍,command一定会执行!
注意:if-then语句的另一种形式如下,通过把分号放在待求值的命令尾部,就可以将then语句放在同一行上了,这样看起来更像其他编程语言中的if-then语句。1
2
3if command; then
commands
fi
2.2.使用if-then-else语句
当if语句中的命令返回退出状态码0时,then部分中的命令会被执行,这跟普通的if-then语句一样。当if语句中的命令返回非零退出状态码时,bash shell会执行else部分中的命令。1
2
3
4
5
6if command
then
commands1
else
commands2
fi
2.3.使用嵌套的if语句
有时你需要检查脚本代码中的多种条件。对此,可以使用嵌套的if-then语句。
书写多个if-then语句会使代码不易阅读,很难理清逻辑流程,因此可以使用else部分的另一种形式:elif。
这样就不用再书写多个if-then语句了。elif使用另一个if-then语句延续else部分。1
2
3
4
5
6
7if command1
then
commands1
elif command2
then
commands2
fi
2.4.test命令
test命令提供了在if-then语句中测试不同条件的途径,可以测试命令退出状态码之外的条件。
如果test命令中列出的条件成立,test命令就会退出并返回退出状态码0。这样if-then语句就与其他编程语言中的if-then语句以类似的方式工作了。如果条件不成立,test命令就会退出并返回非零的退出状态码,这使得if-then语句不会再被执行。test命令的格式非常简单:1
2test condition
# condition是test命令要测试的一系列参数和值
注意:如果不写test命令的condition部分,它会以非零的退出状态码退出,并执行else语句块。
注意:bash shell提供了另一种条件测试方法,无需在if-then语句中声明test命令,即使用方括号定义测试条件,如if [ condition ]注意,第一个方括号之后和第二个方括号之前必须加上一个空格,否则就会报错。
test命令判断三类条件:①数值比较;②字符串比较;③文件比较。
数值比较
| 比较 | 含义 | 描述 |
|---|---|---|
n1 -eq n2 |
equal |
检查n1是否与n2相等 |
n1 -ge n2 |
greater or equal |
检查n1是否大于或等于n2 |
n1 -gt n2 |
greater than |
检查n1是否大于n2 |
n1 -le n2 |
less or equal |
检查n1是否小于或等于n2 |
n1 -lt n2 |
less than |
检查n1是否小于n2 |
n1 -ne n2 |
not equal |
检查n1是否不等于n2 |
注意:bash shell只能处理整数,不能在test命令中使用浮点值。
字符串比较
| 比较 | 描述 | 备注 |
|---|---|---|
str1 = str2 |
检查str1是否和str2相同 | 考虑标点和大小写情况 |
str1 != str2 |
检查str1是否和str2不同 | 考虑标点和大小写情况 |
str1 < str2 |
检查str1是否比str2小 | 需转义,注意顺序 |
str1 > str2 |
检查str1是否比str2大 | 需转义,注意顺序 |
-n str1 |
检查str1是否长度非0 | 「非0」和「为0」恰好相反 |
-z str1 |
检查str1是否长度为0 | 空的和未初始化的变量长度为0 |
注意:比较字符串的大小时,大于号和小于号必须转义,否则shell会把它们当作重定向符号,把字符串值当作文件名。
注意:比较字符串的大小时,大于和小于顺序和sort命令所采用的不同:在比较测试中,大写字母被认为是小于小写字母的,但sort命令恰好相反。
注意:空的和未初始化的变量会对shell脚本测试造成灾难性的影响。如果不是很确定一个变量的内容,最好在将其用于数值或字符串比较之前先通过-n或-z来测试一下变量是否含有值。
文件比较
文件比较很有可能是shell编程中最为强大、也是用得最多的比较形式。它允许你测试Linux文件系统上文件和目录的状态。
| 比较 | 含义 | 描述 | 备注 |
|---|---|---|---|
-d file |
directory |
检查file是否存在并是一个目录 | —— |
-e file |
exist |
检查file是否存在 | 可用于文件和目录 |
-f file |
file |
检查file是否存在并是一个文件 | —— |
-r file |
readable |
检查file是否存在并可读 | —— |
-s file |
—— | 检查file是否存在并非空 | 状态码0说明有数据 |
-w file |
writable |
检查file是否存在并可写 | 判断你对文件是否有可写权限 |
-x file |
executable |
检查file是否存在并可执行 | —— |
-O file |
Owner |
检查file是否存在并属当前用户所有 | 测试你是否是文件的属主 |
-G file |
Group |
检查file是否存在并且默认组与当前用户相同 | 检查文件的默认组 非用户所属所有组 |
file1 -nt file2 |
new than |
检查file1是否比file2新 | 指创建日期,越早创建越旧 |
file1 -ot file2 |
old than |
检查file1是否比file2旧 | 指创建日期,越早创建越旧 |
注意:在使用-nt或-ot比较文件之前,必须先确认文件是存在的,因为他们都不会先检查文件是否存在,所以会导致直接运行了else部分。
2.5.复合条件测试
if-then语句允许使用布尔逻辑来组合测试,布尔逻辑是一种能够将可能的返回值简化为TRUE或FALSE的方法。有AND和OR两种布尔运算符可用:1
2[ condition1 ] && [ condition2 ]
[ condition1 ] || [ condition2 ]
2.6.if-then的高级特性
bash shell提供了两项可在if-then语句中使用的高级特性:
- ①用于数学表达式的双括号
(( expression ))。expression可以是任意的数学赋值或比较表达式。除了test命令使用的标准数学运算符,双括号命令中会用到的其他运算符还有:val++,后增;val--,后减;++val,先增;--val,先减;!,逻辑求反;~,位求反;**,幂运算;<<,左位移;>>,右位移;&,位布尔和;|,位布尔或;&&,逻辑和;||,逻辑或。
注意⑴:可以在if语句中用双括号命令,也可以在脚本中的普通命令里使用来赋值。
注意⑵:不需要将双括号中表达式里的大于号转义,这是双括号命令提供的另一个高级特性。 - ②用于高级字符串处理功能的双方括号
[[ expression ]],注意不是所有的shell都支持双方括号。与test命令相比主要是指「模式匹配(pattern matching)」,例如:在上例中我们使用了双等号(1
2
3
4
5
6
7
# using pattern matching
if [[ $USER == h* ]]; then
echo "Hello $USER."
else
echo "Sorry, I do not know you."
fi==)将右边的字符串(h*)视为一个模式,并应用模式匹配规则。运行该脚本将输出「Hello hwame.」。
2.7.case命令
case命令采用列表格式来检查单个变量的多个值,而不需要再写出所有的elif语句来不停地检查同一个变量的值了:1
2
3
4
5case variable in
pattern1 | pattern2) commands1;;
pattern3) commands2;;
*) commands_default;;
esaccase命令提供了一个更清晰的方法来为变量每个可能的值指定不同的选项,将指定的变量与不同模式进行比较。
如果变量和模式是匹配的,那么shell会执行为该模式指定的命令。可以通过单竖线操作符在一行中分隔出多个模式模式。星号会捕获所有与已知模式不匹配的值。
3.循环语句
3.1.for命令
重复执行一系列命令在编程中很常见,for循环不用说,基本格式如下:1
2
3
4for var in list
do
commands
donefor命令读取值的方式有:①从列表中读取值;②从变量读取列表;③从命令读取值;④用通配符读取目录。
注意:列表中各值按空格依次排列,不需要括号。
注意:考虑下例,第2行输出将两个单引号间的部分拼接到don和ll中间了。这种问题可以采用①使用转义字符\将单引号转义;②使用双引号来定义用到单引号的值。1
2
3
4
5
6
7
8
9
for test in I don't know if this'll work; do
echo "word:$test"
done
# 以下为输出:
word:I
word:dont know if thisll
word:work
注意:for循环假定每个值都是用空格分割的。如果在单独的数据值中有空格,就必须用双引号将这些值圈起来。
注意:在某个值两边使用双引号时,shell并不会将双引号当成值的一部分。
通常shell脚本遇到的情况是,你将一系列值都集中存储在了一个变量中,然后需要遍历变量中的整个列表。也可以通过for命令完成这个任务,例如:
注意,代码还是用了另一个赋值语句向$list变量包含的已有列表中添加(或者说是拼接)了一个值。这是向变量中存储的已有文本字符串尾部添加文本的一个常用方法:list=$list" Connecticut"。1
2
3
4
5
6
7
list="Alabama Alaska Arizona Arkansas Colorado"
list=$list" Connecticut"
for state in $list
do
echo "Have you ever visited $state?"
done
上述代码中,shell以空格分隔列表,事实上是由特殊的环境变量IFS(Internal Field Separator,内部字段分隔符)控制。默认情况下, bash shell会将「空格」、「制表符」、「换行符」当作字段分隔符。
如果需要临时使用新的字段分隔符,可以先保存旧值,使用完新值后再还原:1
2
3
4IFS.OLD=$IFS
IFS=$'\n'
<在代码中使用新的IFS值>
IFS=$IFS.OLD
如果要指定多个IFS字符,只要将它们在赋值行串起来就行:IFS=$'\n':;",这个赋值会将换行符、冒号、分号和双引号作为字段分隔符。如何使用IFS字符解析数据没有任何限制。
可以用for命令来自动遍历目录中的文件。进行此操作时,必须在文件名或路径名中使用通配符。它会强制shell使用文件扩展匹配。文件扩展匹配是生成匹配指定通配符的文件名或路径名的过程。
也可以在for命令中列出多个目录通配符,将目录查找和列表合并进同一个for语句。
注意:在Linux中,目录名和文件名中包含空格当然是合法的。要适应这种情况,应该将$file变量用双引号圈起来:if [ -d "$file" ]。如果不这么做,遇到含有空格的目录名或文件名时就会有错误产生:[: too many arguments,在test命令中,bash shell会将额外的单词当作参数,进而造成错误。
3.2.C语言风格的for命令
下面为C语言代码:1
2
3
4for (i = 0; i < 10; i++)
{
printf("The next number is %d\n", i);
}
以下是bash中C语言风格的for循环的基本格式:1
2for (( variable assignment ; condition ; iteration process ))
for (( a = 1; a < 10; a++ ))
注意,有些部分并没有遵循bash shell标准的for命令:
- 变量赋值可以有空格;
- 条件中的变量不以美元符开头;
- 迭代过程的算式未用expr命令格式。
C语言风格的for命令也允许为迭代使用多个变量。循环会单独处理每个变量,你可以为每个变量定义不同的迭代过程。尽管可以使用多个变量,但你只能在for循环中定义一种条件,例如for (( a=1, b=10; a <= 10; a++, b-- ))。
3.3.while命令
while命令某种意义上是if-then语句和for循环的混杂体:1
2
3
4while test_command
do
commands
donewhile命令中定义的test_command和if-then语句中的格式一模一样。可以使用任何普通的bash shell命令,或者用test命令进行条件测试,比如测试变量值。while命令的关键在于所指定的test_command的退出状态码必须随着循环中运行的命令而改变。如果退出状态码不发生变化,while循环就将一直不停地进行下去从而陷入无限循环。
最常见的test_command的用法是用方括号来检查循环命令中用到的shell变量的值,while命令定义了每次迭代时检查的测试条件。
while命令允许你在while语句行定义多个测试命令。只有最后一个测试命令的退出状态码会被用来决定什么时候结束循环,见下例。1
2
3
4
5
6
7
8
var1=10
while echo $var1
[ $var1 -ge 0 ]
do
echo "This is inside the loop"
var1=$[ $var1 - 1 ]
done
运行结果如图: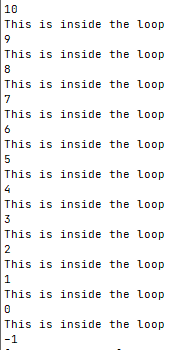
while循环会在var1变量等于0时执行echo语句,然后将var1变量的值减一。接下来再次执行测试命令,用于下一次迭代。echo测试命令被执行并显示了var变量的值(现在小于0了)。直到shell执行test测试命令,while循环才会停止。
这说明在含有多个命令的while语句中,在每次迭代中所有的测试命令都会被执行,包括测试命令失败的最后一次迭代。要留心这种用法。另一处要留意的是该如何指定多个测试命令。注意,每个测试命令都出现在单独的一行上。
3.4.until命令
until命令和while命令工作的方式完全相反。until命令要求你指定一个通常返回非零退出状态码的测试命令。只有测试命令的退出状态码不为0,bash shell才会执行循环中列出的命令。一旦测试命令返回了退出状态码0,循环就结束了。1
2
3
4until command
do
commands
done
和while命令类似,你可以在until命令语句中放入多个测试命令。只有最后一个命令的退出状态码决定了bash shell是否执行已定义的commands,例如:1
2
3
4
5
6
7
8
var1=100
until echo $var1
[ $var1 -eq 0 ]
do
echo Inside the loop: $var1
var1=$[ $var1 - 25 ]
done
运行结果如图,shell会执行指定的多个测试命令,只有在最后一个命令成立时停止。
3.5.嵌套循环
循环语句可以在循环内使用任意类型的命令,包括其他循环命令,这种循环叫作嵌套循环(nested loop),被嵌套的循环也称为内部循环(inner loop)。
内外循环的两个do和done命令没有任何差别。bash shell知道当第一个done命令执行时是指内部循环而非外部循环。
在混用循环命令时也一样,比如在while循环内部放置一个for循环,或者在until循环内部放置一个while循环。1
2
3
4
5
6
7
8
9
10
11
12
13
# using until and while loops
var1=3
until [ $var1 -eq 0 ]; do
echo "Outer loop: $var1"
var2=1
while [ $var2 -lt 5 ]; do
var3=$(echo "scale=4; $var1 / $var2" | bc)
echo " Inner loop: $var1 / $var2 = $var3"
var2=$[ $var2 + 1 ]
done
var1=$[ $var1 - 1 ]
done
运行结果如图,外部的until循环以值3开始,并继续执行到值等于0。内部while循环以值1开始并一直执行,只要值小于5。每个循环都必须改变在测试条件中用到的值,否则循环就会无止尽进行下去。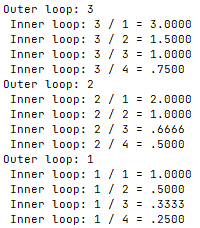
3.6.循环处理文件数据
通常必须遍历存储在文件中的数据,这需要使用到上文提到的①使用嵌套循环;②修改IFS环境变量。
典型的例子是处理/etc/passwd文件中的数据。这要求你逐行遍历该文件,并将IFS变量的值改成冒号,这样就能分隔开每行中的各个数据段了。1
2
3
4
5
6
7
8
9
10
11
12
IFS.OLD=$IFS
IFS=$'\n'
for entry in $(cat /etc/passwd)
do
echo "Values in $entry –"
IFS=:
for value in $entry
do
echo " $value"
done
done
3.7.控制循环
break命令和continue命令能帮我们控制循环内部的情况,而不必等到循环完成所有的迭代:
break命令:用来退出任意类型的循环,包括while和until循环。break命令接受单个命令行参数值:break n,其中n指定了要跳出的循环层级。默认情况下跳出的是当前的循环(即省略n时为n=1);如果你n设为2就会停止下一级的外部循环。continue命令:continue命令可以提前中止某次循环中的命令,但并不会完全终止整个循环。亦即停止当前进行的一次迭代,直接进入下一次迭代,注意仍在同级循环中。
和break命令一样,continue命令也允许通过命令行参数指定要继续执行哪一级循环:continue n,其中n定义了要继续的循环层级。
注意:可以在while和until循环中使用continue命令,但要特别小心。记住,当shell执行continue命令时,它会跳过剩余的命令。如果你在其中某个条件里对测试条件变量进行增值,问题就会出现:1
2
3
4
5
6
7
8
9
10
11
12
13
# improperly using the continue command in a while loop
var1=0
while echo "while iteration: $var1"
[ $var1 -lt 15 ]
do
if [ $var1 -gt 5 ] && [ $var1 -lt 10 ]
then
continue
fi
echo " Inside iteration number: $var1"
var1=$[ $var1 + 1 ]
done
由于该程序会陷入死循环,因此可以将脚本的输出重定向到了more命令:./mytest | more,这样才能停止输出。运行结果如下: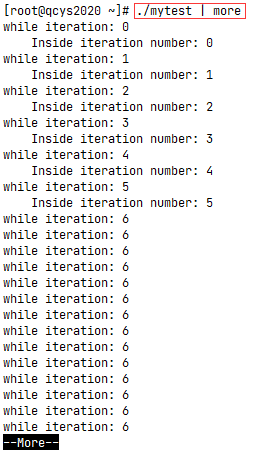
在if-then的条件成立之前,所有一切看起来都很正常,然后shell执行了continue命令。当shell执行continue命令时,它跳过了while循环中余下的命令。不幸的是,被跳过的部分正是$var1计数变量增值的地方,而这个变量又被用于while测试命令中,这意味着这个变量的值不会再变化了,从前面连续的输出显示中你也可以看出来。
下面是继续外部for循环的一个例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# continuing an outer loop
for (( a = 1; a <= 5; a++ ))
do
echo "Iteration $a:"
for (( b = 1; b < 3; b++ ))
do
if [ $a -gt 2 ] && [ $a -lt 4 ]
then
continue 2
fi
var3=$[ $a * $b ]
echo " The result of $a * $b is $var3"
done
done
其中的if-then语句用continue命令来停止处理循环内的命令,但会继续处理外部循环。注意,值为3的那次迭代并没有处理任何内部循环语句,因为尽管continue命令停止了处理过程,但外部循环依然会继续。运行结果如图: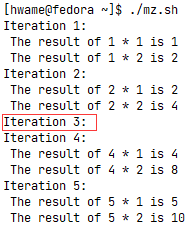
3.8.处理循环的输出
在shell脚本中,你可以对循环的输出使用管道或进行重定向,这可以通过在done命令之后添加一个处理命令来实现。
可以将循环的结果通过管道管接给另一个命令,例如将for命令的输出传给了sort命令,该命令会改变for命令输出结果的顺序,注意结果已经在脚本内部排好序了。
例如下面将for命令的输出重定向到文件的例子,在for命令之后正常显示了echo语句:1
2
3
4
5
6
for (( a = 1; a < 10; a++ ))
do
echo "The number is $a"
done > output.txt
echo "The command is finished."
运行结果如图: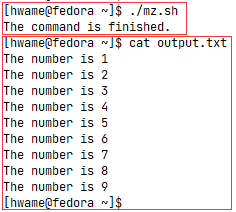
4.处理用户输入
4.1.命令行参数
向shell脚本传递数据的最基本方法是使用命令行参数,他允许在运行脚本时向命令行添加数据,例如./mytest 10 30向脚本mytest传递了两个命令行参数(10和30)。脚本会通过特殊的变量来处理命令行参数。
bash shell会将一些称为位置参数(positional parameter)的特殊变量分配给输入到命令行中的所有参数,这也包括shell所执行的脚本名称。
位置参数变量是标准的数字:$0是程序名,$1是第一个参数,$2是第二个参数,依次类推,直到第九个参数$9。如果脚本需要的命令行参数不止9个,则必须在变量数字周围加上花括号,比如${10}。
如果需要输入更多的命令行参数,则每个参数都必须用空格分开,shell会将每个参数分配给对应的变量。要在参数值中包含空格,必须要用引号(单引号或双引号均可)。
注意:将文本字符串作为参数传递时,引号并非数据的一部分,它们只是表明数据的起止位置。
注意:利用$0读取脚本名时存在一个潜在的问题,即$0参数会同时包含路径和连在一起的命令,如下表所示。解决这个问题只需要使用basename命令,他会返回不包含路径的脚本名:basename $0,例如script=$(basename $0)。
| 执行命令 | $0变量 |
备注 |
|---|---|---|
bash mz.sh |
mz.sh |
没有问题 |
./mz.sh |
./mz.sh |
包含命令 |
bash /home/hwame/mz.sh |
/home/hwame/mz.sh |
包含路径 |
在shell脚本中使用命令行参数时要小心些。当脚本认为参数变量中会有数据而实际上并没有时,脚本很有可能会产生错误消息。
通俗的说,当脚本中使用了变量$1、$2、$3时,如果允许脚本时没有给出对应的命令行参数则会报错。
因此在使用参数前一定要检查其中是否存在数据,一种方法是使用-n测试来检查命令行参数$1中是否有数据:if [ -n "$1"]; then。
4.2.特殊参数变量
如果每次都在脚本中使用之前检查一下命令行参数,无疑比较麻烦。bash shell为此提供了一个
特殊变量$#,他含有脚本运行时携带的命令行参数的个数。可以在脚本中任何地方使用这个特殊变量,就跟普通变量一样。注意,变量$#的值不包括脚本名称。
那么问题来了。既然$#变量含有参数的总数,那么变量${$#}就代表了最后一个命令行参数变量。然而并不是这样,你不能在花括号内使用美元符,必须将美元符换成感叹号即${!#}。很奇怪,但不讲道理。我们也可以拆分一下,将$#赋值给一个变量params然后再使用params变量:1
2
3
4
5
# Grabbing the last parameter
params=$#
echo The last parameter is $params
echo The last parameter is ${!#}
上述示例中的两种方式都没问题。但要注意,当命令行上没有任何参数时,$#的值为0,params变量的值也一样,但${!#}变量会返回命令行用到的脚本名。
有时候需要抓取命令行上提供的所有参数,希望能够在单个变量中存储所有的命令行参数,而不是先用$#变量来判断命令行上有多少参数,然后再进行遍历。
可以使用一组其他的特殊变量$*和$@来解决这个问题:
$*变量会将命令行上提供的所有参数当作一个单词保存,这个单词包含了命令行中出现的每一个参数值。基本上$*变量会将这些参数视为一个整体,而不是多个个体。$@变量会将命令行上提供的所有参数当作同一字符串中的多个独立的单词。通常通过for命令遍历所有的参数值,得到每个参数。
通过使用for命令遍历这两个特殊变量,可以看到它们是如何不同地处理命令行参数的。 $*变量会将所有参数当成单个参数,而$@变量会单独处理每个参数。这是遍历命令行参数的一个绝妙方法。二者之间的差异见下例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
count=1
for param in "$*"
do
echo "\$* Parameter #$count = $param"
count=$[ $count + 1 ]
done
echo
count=1
for param in "$@"
do
echo "\$@ Parameter #$count = $param"
count=$[ $count + 1 ]
done
运行结果如图:
4.3.移动变量
bash shell的shift命令能够用来操作命令行参数。顾名思义,他会根据它们的相对位置来移动命令行参数。
默认情况下它会将每个参数变量向左移动一个位置。所以,变量$3的值会移到$2中,变量$2的值会移到$1中,而变量$1的值则会被删除(注意,变量$0的值即程序名不会改变)。也可以一次性移动多个位置,只需要给shift命令提供一个参数指明要移动的位置数就行了:shift n。
注意:如果某个参数被移出,它的值就被丢弃了,无法再恢复。
这是遍历命令行参数的另一个好方法,尤其是在你不知道到底有多少参数时。你可以只操作第一个参数,移动参数,然后继续操作第一个参数,例如:1
2
3
4
5
6
7
count=1
while [ -n "$1" ]; do
echo "Parameter #$count = $1"
count=$[ $count + 1 ]
shift
done
运行结果如图所示: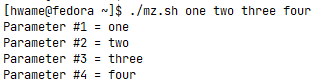
4.4.处理选项
「选项」是跟在单破折线后面的单个字母,它能改变命令的行为,此处介绍3种在脚本中处理选项的方法。
(1)查找选项
表面上看,命令行选项也没什么特殊的。在命令行上,它们紧跟在脚本名之后,就跟命令行参数一样。实际上,如果愿意,你可以像处理命令行参数一样处理命令行选项。
- ①处理简单选项:可以用
shift命令来处理脚本程序携带的命令行选项,用case语句来判断某个参数是否为选项。case语句会检查每个参数是不是有效选项,如果是就运行对应语句中的命令。不管选项按什么顺序出现在命令行上,这种方法都适用。示例如下:1
2
3
4
5
6
7
8
9
10
11
# extracting command line options as parameters
while [ -n "$1" ]; do
case "$1" in
-a) echo "Found the -a option" ;;
-b) echo "Found the -b option" ;;
-c) echo "Found the -c option" ;;
*) echo "$1 is not an option" ;;
esac
shift
done - ②分离参数和选项:对于在shell脚本中同时使用选项和参数的情况,标准方式是用特殊字符(双破折线
--)来将二者分开,该字符会告诉脚本何时选项结束以及普通参数何时开始。
shell会用双破折线来表明选项列表结束。在双破折线之后,脚本就可以放心地将剩下的命令行参数当作参数,而不是选项来处理了。要检查双破折线,只要在case语句中加一项就行了,如下例所示:运行结果如图,可以看出,第一次未分离时脚本认为所有的命令行参数都是选项;第二次使用1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# extracting options and parameters
while [ -n "$1" ]; do
case "$1" in
-a) echo "Found the -a option" ;;
-b) echo "Found the -b option" ;;
-c) echo "Found the -c option" ;;
--) shift
break ;;
*) echo "$1 is not an option" ;;
esac
shift
done
count=1
for param in $@; do
echo "Parameter #$count: $param"
count=$[ $count + 1 ]
done--分离后,当脚本遇到双破折线时,它会停止处理选项,并将剩下的参数都当作命令行参数。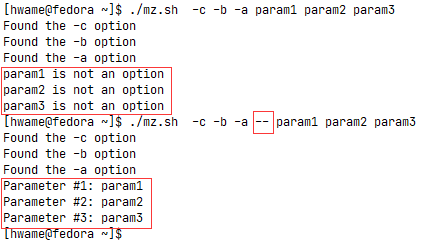
- ③处理带值的选项:有些选项会带上一个额外的参数值,例如:
./mz.sh -a test1 -b -c -d test2。当命令行选项要求额外的参数时,脚本必须能检测到并正确处理,如下例:在这个例子中,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# extracting command line options and values
while [ -n "$1" ]; do
case "$1" in
-a) echo "Found the -a option";;
-b) param="$2"
echo "Found the -b option, with parameter value $param"
shift ;;
-c) echo "Found the -c option";;
--) shift
break ;;
*) echo "$1 is not an option";;
esac
shift
done
count=1
for param in "$@"; do
echo "Parameter #$count: $param"
count=$[ $count + 1 ]
donecase语句定义了三个它要处理的选项,其中-b选项还需要一个额外的参数值。由于要处理的参数是$1,额外的参数值就应该位于$2(因为所有的参数在处理完之后都会被移出)。只要将参数值从$2变量中提取出来就可以了。当然,因为这个选项占用了两个参数位,所以你还需要使用shift命令多移动一个位置。运行结果如图: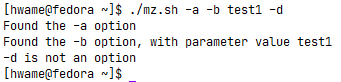
(2)getopt命令
上述shell脚本已经有了处理命令行选项的基本能力,但还有一些限制。比如,合并选项是Linux中一个很常见的用法,如果你想将多个选项放进一个参数中时,它就不能工作了。getopt命令是一个在处理命令行选项和参数时非常方便的工具。它能够识别命令行参数,从而在脚本中解析它们时更方便。
命令格式:getopt optstring parameters。optstring是这个过程的关键所在,它定义了命令行有效的选项字母,还定义了哪些选项字母需要参数值。
首先,在optstring中列出你要在脚本中用到的每个命令行选项字母。然后,在每个需要参数值的选项字母后加一个冒号。getopt命令会基于你定义的optstring解析提供的参数。
举例如图:
命令行getopt ab:cd -a -b test1 -cd test2 test3中的optstring定义了四个有效选项字母:a、b、c和d。冒号(:)被放在了字母b后面,因为b选项需要一个参数值。当getopt命令运行时,它会检查提供的参数列表(-a -b test1 -cd test2 test3),并基于提供的optstring进行解析。注意,它会自动将-cd选项分成两个单独的选项,并插入双破折线来分隔行中的额外参数test2 test3。
注意:如果指定了一个不在optstring中的选项,默认情况下getopt命令会产生一条错误消息,可以在命令后加-q选项来忽略这条错误消息。如下图所示: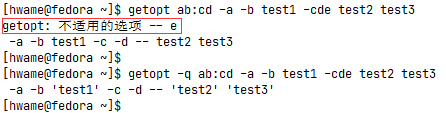
可以在脚本中使用getopt来格式化脚本所携带的任何命令行选项或参数,但用起来略微复杂。
用getopt命令生成的格式化后的版本来替换已有的命令行选项和参数,set命令的选项之一是双破折线--,它会将命令行参数替换成set命令的命令行值。
该方法会将原始脚本的命令行参数传给getopt命令,之后再将getopt命令的输出传给set命令,用getopt格式化后的命令行参数来替换原始的命令行参数,格式看起来如下所示:set -- $(getopt -q ab:cd "$@")。
现在原始的命令行参数变量的值会被getopt命令的输出替换,而getopt已经为我们格式化
好了命令行参数。利用该方法就可以写出能帮我们处理命令行参数的脚本:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
set -- $(getopt -q ab:cd "$@")
while [ -n "$1" ]; do
case "$1" in
-a) echo "Found the -a option" ;;
-b) param="$2"
echo "Found the -b option, with parameter value $param"
shift ;;
-c) echo "Found the -c option" ;;
--) shift
break ;;
*) echo "$1 is not an option";;
esac
shift
done
count=1
for param in "$@"; do
echo "Parameter #$count: $param"
count=$[ $count + 1 ]
done
注意到该例和上文查找选项中第三种情况「处理带值的选项」一样,唯一不同的是加入了getopt命令来帮助格式化命令行参数。并且可以运行带有复杂选项的脚本如合并的选项:./mz.sh -ac,同时之前的功能照样没有问题。
(3)更高级的getopts命令
然而,getopt命令并不擅长处理带空格和引号的参数值,它会将空格当作参数分隔符,而不是根据双引号将二者当作一个参数。
getopts命令(注意是复数)内建于bash shell,它跟近亲getopt看起来很像,但多了一些扩展功能。getopt将命令行上选项和参数处理后只生成一个输出,而getopts命令能够和已有的shell参数变量配合默契。
每次调用getopts时,它一次只处理命令行上检测到的一个参数。处理完所有的参数后,它会退出并返回一个大于0的退出状态码。这让它非常适合用于解析命令行所有参数的循环中。
getopts命令的格式如下:getopts optstring variable。optstring值类似于getopt命令中的那个。有效的选项字母都会列在optstring中,如果选项字母要求有个参数值,就加一个冒号。要去掉错误消息的话,可以在optstring之前加一个冒号。getopts命令将当前参数保存在命令行中定义的variable中。getopts命令会用到两个环境变量:OPTARG环境变量保存选项需要跟的一个参数值;OPTIND环境变量保存了参数列表中getopts正在处理的参数位置。这样你就能在处理完选项之后继续处理其他命令行参数了。1
2
3
4
5
6
7
8
9
10
11
# simple demonstration of the getopts command
while getopts :ab:c opt
do
case "$opt" in
a) echo "Found the -a option" ;;
b) echo "Found the -b option, with value $OPTARG";;
c) echo "Found the -c option" ;;
*) echo "Unknown option: $opt";;
esac
donewhile语句定义了getopts命令,指明了要查找哪些命令行选项,以及每次迭代中存储它们的变量名(opt)。注意到在本例中case语句的用法有些不同:getopts命令解析命令行选项时会移除开头的单破折线,所以在case定义中不用单破折线。getopts命令有几个好用的功能:①可以在参数值中包含空格;②可以将选项字母和参数值放在一起使用,而不用加空格,getopts命令能够从选项中正确解析出参数值;③可以将命令行上所有未定义的选项统一输出成问号,以问号形式发送给代码。
上述代码运行结果如图:
getopts命令知道何时停止处理选项,并将参数留给你处理。在getopts处理每个选项时,它会将OPTIND环境变量值增一。在getopts完成处理时,你可以使用shift命令和OPTIND值来移动参数。如下例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
while getopts :ab:cd opt
do
case "$opt" in
a) echo "Found the -a option" ;;
b) echo "Found the -b option, with value $OPTARG" ;;
c) echo "Found the -c option" ;;
d) echo "Found the -d option" ;;
*) echo "Unknown option: $opt" ;;
esac
done
shift $[ $OPTIND - 1 ]
count=1
for param in "$@"
do
echo "Parameter $count: $param"
count=$[ $count + 1 ]
done
运行结果如图:
4.5.将选项标准化
所谓选项标准化,就是尽量遵循某些字母选项在Linux世界里已经拥有的某种程度的标准含义,而不是随意决定用哪些字母选项以及它们的用法,将选项标准化使得脚本看起来能更友好一些。常用的Linux命令选项如下:
| 选项 | 含义 | 描述 |
|---|---|---|
-a |
all |
显示所有对象 |
-c |
count |
生成一个计数 |
-d |
directory |
指定一个目录 |
-e |
extend |
扩展一个对象 |
-f |
file |
指定读入数据的文件 |
-h |
help |
显示命令的帮助信息 |
-i |
ignorecase |
忽略文本大小写 |
-l |
long |
产生输出的长格式版本 |
-n |
non-interactive |
使用非交互模式(批处理) |
-o |
output redirect |
将所有输出重定向到指定的输出文件 |
-q-s |
quietsilent |
以安静模式运行 |
-r |
recursive |
递归地处理目录和文件 |
-v |
verbose |
生成详细输出 |
-x |
exclude |
排除某个对象 |
-y |
yes |
对所有问题回答yes |
4.6.获得用户输入
尽管命令行选项和参数是从脚本用户处获得输入的一种重要方式,但有时脚本的交互性还需要更强一些。比如你想要在脚本运行时问个问题,并等待运行脚本的人来回答。bash shell为此提供了read命令。
(1)基本的读取
read命令从标准输入(键盘)或另一个文件描述符中接受输入,在收到输入后会将数据放进一个指定的变量。例如:1
2
3
4
echo -n "Enter your name: "
read name
echo "Hello $name, welcome to my program. "
注意,上例中生成提示的echo命令使用了-n选项。该选项不会在字符串末尾输出换行符,允许脚本用户紧跟其后输入数据,而不是下一行。这让脚本看起来更像表单。
实际上,read命令包含了-p选项,允许你直接在read命令行指定提示符。例如:1
2
3
4
read -p "Please enter your age: " age
days=$[ $age * 365 ]
echo "That makes you over $days days old! "read命令也允许指定多个变量,输入的每个数据值都会分配给变量列表中的下一个变量。如果变量数量不够,剩下的数据就全部分配给最后一个变量。是不是和Python中的*args和**kwargs有点像呢?
也可以在read命令行中不指定变量,这样它收到的任何数据都会放进特殊环境变量REPLY中。REPLY环境变量会保存输入的所有数据,可以在shell脚本中像其他变量一样使用。
(2)超时
如果不管是否有数据输入,脚本都必须继续执行,你可以用-t选项来指定一个计时器,他指定了read命令等待输入的秒数。当计时器过期后,read命令会返回一个非零退出状态码,可以使用if-then语句或while循环这种标准的结构化语句来理清所发生的具体情况。
也可以不对输入过程计时,而是让read命令来统计输入的字符数。当输入的字符达到预设的字符数时,就自动退出,将输入的数据赋给变量。可以将-n选项和值1一起使用,告诉read命令在接受单个字符后退出。只要按下单个字符回答后,read命令就会接受输入并将它传给变量,无需按回车键。1
2
3
4
5
6
7
8
9
10
read -n1 -p "Do you want to continue [Y/N]? " answer
case $answer in
Y | y) echo
echo "fine, continue on…";;
N | n) echo
echo OK, goodbye
exit;;
esac
echo "This is the end of the script"
运行结果如图: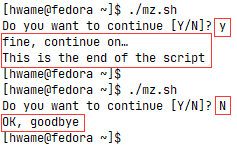
(3)隐藏方式读取
当需要输入类似密码这种需要从脚本用户处得到输入,但又在屏幕上显示输入信息时,可以使用-s选项不回显终端的输入(实际上数据会被显示,只是read命令会将文本颜色设成跟背景色一样)。输入提示符输入的数据不会出现在屏幕上,但会赋给变量,以便在脚本中使用。例如:read -s -p "Enter your password: " password。
(4)从文件中读取
可以用read命令来读取文件里的数据,每次调用read命令都会从文件中读取一行文本。当文件中再没有内容时,read命令会退出并返回非零退出状态码。
如何将文件中的数据传给read命令呢?最常见的方法是对文件使用cat命令,将结果通过管道直接传给含有read命令的while命令。见下例:1
2
3
4
5
6
7
8
count=1
cat textfile | while read line
do
echo "Line $count: $line"
count=$[ $count + 1]
done
echo "Finished processing the file"
文件textfile内容及运行结果如下: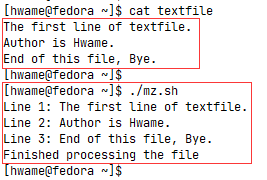
5.创建函数
5.1.基本脚本函数
函数是一个脚本代码块,你可以为其命名并在代码中任何位置重用,调用函数(在脚本中使用该代码块)时只要使用所起的函数名就行了。
创建函数的第一种格式是采用关键字function,后跟分配给该代码块的函数名:name属性定义了赋予函数的唯一名称,脚本中定义的每个函数都必须有一个唯一的名称。commands是构成函数的一条或多条bash shell命令,在调用该函数时会按命令在函数中出现的顺序依次执行,就像在普通脚本中一样。1
2
3function name {
commands
}
创建函数的第二种格式更接近于其他编程语言中定义函数的方式:
函数名后的空括号表明正在定义的是一个函数,这种格式的命名规则和之前定义shell脚本函数的格式一样。1
2
3name() {
commands
}
至于使用函数,只需要像其他shell命令一样,在行中指定函数名就行了。
注意①:函数定义不一定非得是shell脚本中首先要做的事,但必须在使用函数之前定义它,否则会收到一条command not found的错误消息。
注意②:函数名必须是唯一的,如果你重定义了函数,新定义会覆盖原来函数的定义,这一切不会产生任何错误消息。
5.2.返回值
bash shell会把函数当作一个小型脚本,运行结束时会返回一个退出状态码,生成退出状态码有以下3种不同的方法:
- 默认退出状态码:默认情况下,函数的退出状态码是函数中最后一条命令返回的退出状态码。在函数执行结束后,可以用标准变量
$?来确定函数的退出状态码。
注意:由于函数的默认退出状态码取决于函数体中最后一条命令的退出状态码,因此你无法知道函数中其他命令中是否成功运行,所以这种方法很危险。 - 使用
return命令:使用return命令来退出函数并返回特定的退出状态码,它允许指定一个整数值来定义函数的退出状态码,从而提供了一种简单的途径来编程设定函数退出状态码。
注意:①函数一结束就取返回值,否则可能会丢失返回值。②退出状态码的范围是0~255,超出则会取余。 - 使用函数输出:正如可以将命令的输出保存到shell变量中一样,你也可以对函数的输出采用同样的处理办法。可以用这种技术来获得任何类型的函数输出,并将其保存到变量中。见下例:注意①:该函数实际上输出了两条消息,
1
2
3
4
5
6
7
function myfunc {
read -p "Enter a value: " value
echo $[ $value * 2 ]
}
result=$(myfunc)
echo "The new value is $result"read命令输出了一条简短的消息来向用户询问输入值,但bash shell并不将其作为STDOUT输出的一部分,并且忽略掉它。如果你用echo语句生成这条消息来向用户查询,那么它会与输出值一起被读进shell变量中。
注意②:这种方法还可以返回浮点值和字符串值,这使它成为一种获取函数返回值的强大方法。上例运行结果如图: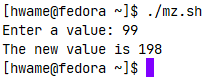
5.3.在函数中使用变量
在函数中使用变量时,你需要注意它们的定义方式以及处理方式——这是shell脚本中常见错误的根源。
向函数传递参数
bash shell会将函数当作小型脚本来对待,这意味着你可以像普通脚本那样向函数传递参数。
函数可以使用标准的参数环境变量来表示命令行上传给函数的参数。例如,函数名会在$0变量中定义,函数命令行上的任何参数都会通过$1、$2等定义。也可以用特殊变量$#来判断传给函数的参数数目。
注意①:在脚本中指定函数时,必须将参数和函数放在同一行,例如func1 $value1 10,result=$(func1 $value1 10);
注意②:由于函数使用特殊参数环境变量作为自己的参数值,因此它无法直接获取脚本在命令行中的参数值。尽管函数也使用了$1和$2变量,但它们和脚本主体中的$1和$2变量并不相同。要在函数中使用这些值,必须在调用函数时手动将它们传过去。1
2
3
4
5
6
7
8
function myfunc {
echo $[ $1 * $2 ]
}
value1=$(myfunc 10 20)
value2=$(myfunc)
value3=$(myfunc $1 $2)
echo "The result is $valuex"
如上例,value1是正常的函数调用方式,将参数和函数放在同一行。如果想让value2以这种方式直接获取命令行参数值将报错:syntax error: operand expected...,原因见上,解决办法就是按value3的方式。尽管在函数的定义和调用时都使用了$1和$2变量,但他们的区别就如同形参和实参。
在函数中处理变量
变量的作用域也会经常带来麻烦,作用域是变量可见的区域。函数中定义的变量与普通变量的作用域不同,也就是说,对脚本的其他部分而言,它们是隐藏的。
函数使用两种类型的变量:全局变量和局部变量。
- 全局变量:在shell脚本中任何地方都有效的变量。如果你在脚本的主体部分定义了一个全局变量,那么可以在函数内读取它的值。类似地,如果你在函数内定义了一个全局变量,可以在脚本的主体部分读取它的值。默认情况下,在脚本中定义的任何变量都是全局变量。在函数外定义的变量可在函数内正常访问。
注意:在使用全局变量时,如果变量被修改后新值将依然有效,这有时会产生难以预料的后果。它要求你清清楚楚地知道函数中具体使用了哪些变量,包括那些用来计算非返回值的变量。 - 局部变量:
local关键字保证了变量只局限在该函数中,如果脚本中在该函数之外有同样名字的变量,那么shell将会保持这两个变量的值是分离的。
如果要将函数内部使用的任何变量都声明成局部变量,只需要在变量声明的前面加上local关键字:local temp。也可以在变量赋值语句中使用local关键字:local temp=$[ $value + 5 ]。
5.4.数组变量和函数
向函数传递数组参数
向脚本函数传递数组变量的方法会有点不好理解。将数组变量当作单个参数传递的话,它不会起作用。见下例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
function testit {
echo "The parameters are: $@"
thisarray=$1
echo "The received array is ${thisarray[*]}"
}
myarray=(1 2 3 4 5)
echo "The original array is: ${myarray[*]}"
testit $myarray
# 运行结果如下:
# The original array is: 1 2 3 4 5
# The parameters are: 1
# The received array is 1
如你所见,如果将该数组变量作为函数参数,函数只会取数组变量的第一个值。要解决这个问题,必须将该数组变量的值分解成单个值,然后将这些值作为函数参数使用。在函数内部,可以将所有的参数重新组合成一个新的变量。
如下例所示,$myarray变量来保存所有的数组元素,然后将它们都放在函数的命令行上。该函数随后从命令行参数中重建数组变量。在函数内部,数组仍然可以像其他数组一样使用。1
2
3
4
5
6
7
8
9
10
11
12
13
function testit {
local newarray
newarray=($(echo "$@"))
echo "The new array value is: ${newarray[*]}"
}
myarray=(1 2 3 4 5)
echo "The original array is ${myarray[*]}"
testit ${myarray[*]}
# 运行结果如下:
# The original array is 1 2 3 4 5
# The new array value is: 1 2 3 4 5
下面是一个遍历数组并将所有元素累加的例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
function addarray {
local sum=0
local newarray
newarray=($(echo "$@"))
for value in ${newarray[*]}
do
sum=$[ $sum + $value ]
done
echo $sum
}
myarray=(1 2 3 4 5)
echo "The original array is: ${myarray[*]}"
arg1=$(echo ${myarray[*]})
result=$(addarray $arg1)
echo "The result is $result"
运行结果如图: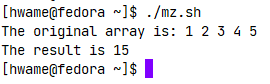
从函数返回数组
从函数里向shell脚本传回数组变量也用类似的方法:函数用echo语句来按正确顺序输出单个数组值,然后脚本再将它们重新放进一个新的数组变量中。见下例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
function returnarray {
local oriarray
local newarray
local elements
local i
oriarray=($(echo "$@"))
newarray=($(echo "$@"))
elements=$[ $# - 1 ]
for (( i = 0; i <= $elements; i++ ))
{
newarray[$i]=$[ ${oriarray[$i]} * 2 ]
}
echo ${newarray[*]}
}
myarray=(1 2 3 4 5)
echo "The original array is: ${myarray[*]}"
arg1=$(echo ${myarray[*]})
result=($(returnarray $arg1))
echo "The new array is: ${result[*]}"
该脚本用$arg1变量将数组值传给returnarray函数,函数将该数组重组到新的数组变量中,生成该输出数组变量的一个副本。然后对数据元素进行遍历,将每个元素值翻倍,并将结果存入函数中该数组变量的副本。returnarray函数使用echo语句来输出每个数组元素的值。脚本用returnarray函数的输出来重新生成一个新的数组变量。运行结果如图: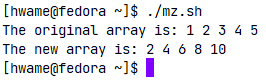
5.5.函数递归
局部函数变量的一个特性是自成体系,除了从脚本命令行处获得的变量,自成体系的函数不需要使用任何外部资源。这个特性使得函数可以递归地调用,也就是说,函数可以调用自己来得到结果。
通常递归函数都有一个最终可以迭代到的基准值。许多高级数学算法用递归对复杂的方程进行逐级规约,直到基准值定义的那级。递归算法的经典例子是计算阶乘:1
2
3
4
5
6
7
8
9
10
11
12
13
14
function factorial {
if [ $1 -eq 1 ]
then
echo 1
else
local temp=$[ $1 - 1 ]
local result=$(factorial $temp)
echo $[ $result * $1 ]
fi
}
read -p "Enter value: " value
result=$(factorial $value)
echo "The factorial of $value is: $result"
运行结果如下: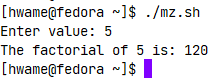
5.6.创建库
bash shell允许创建函数库文件,然后在多个脚本中引用该库文件。
第一步需要创建一个包含脚本中所需函数的公用库文件,例如定义了3个简单的函数的库文件myfuncs。第二步就是在用到这些函数的脚本文件中包含该库文件,但是问题就来了。
和环境变量一样,shell函数仅在定义它的shell会话内有效。如果你在shell命令行界面的提示符下运行
myfuncs的shell脚本,shell会创建一个新的shell并在其中运行这个脚本。它会为那个新shell定义这三个函数,但当你运行另外一个要用到这些函数的脚本时,它们是无法使用的。
这同样适用于脚本:如果你尝试像普通脚本文件那样运行库文件,函数并不会出现在脚本中。例如运行下例将报错addem: command not found:
2
3
4
5
./myfuncs
# 库文件中的函数addem将两数相加
result=$(addem 10 15)
echo "The result is $result"
使用函数库的关键在于source命令。 source命令会在当前shell上下文中执行命令,而不是创建一个新shell。可以用source命令来在shell脚本中运行库文件脚本。这样脚本就可以使用库中的函数了。source命令有个快捷的别名.,称作点操作符(dot operator)。要在shell脚本中运行myfuncs库文件,只需添加:. ./myfuncs。如果库文件和shell脚本不是位于同一目录,则需要使用相应路径访问该库文件。
5.7.在命令行上使用函数
和在shell脚本中将脚本函数当命令使用一样,在命令行界面的提示符下你也可以直接使用这些函数。一旦在shell中定义了函数,你就可以在整个系统中使用它了,无需担心脚本是不是在PATH环境变量里。
重点在于让shell能够识别这些函数,有以下两种方法:
- 在命令行上创建函数;
- 在
.bashrc文件中定义函数。
对于简单的函数,可以在命令行上直接定义一个函数,因为shell会解释用户输入的命令。如果采用单行方式定义函数,必须在每个命令后面加个分号,这样shell就能知道在哪里是命令的起止了;如果采用多行方式定义函数,则不需要添加分号,只需要回车即可。如图所示: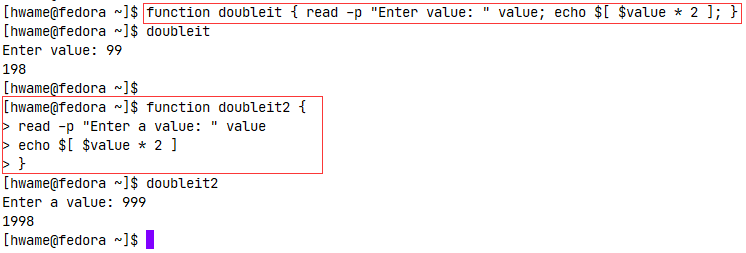
注意:在命令行上创建函数时,如果你给函数起了个跟内建命令或另一个命令相同的名字,函数将会覆盖原来的命令。
在命令行上创建函数不仅输入不便,而且最主要的问题是退出shell时函数就消失了。最简单的解决办法就是将函数定义在.bashrc文件中,bash shell在每次启动时都会在主目录下查找这个文件,不管是交互式shell还是从现有shell中启动的新shell。
- 直接定义函数,可以直接在主目录下的
.bashrc文件中定义函数。许多Linux发行版已经在.bashrc文件中定义了一些东西,所以注意不要误删了,把你写的函数放在文件末尾就行了。 - 读取函数文件,只要是在shell脚本中,都可以用
source命令(或者它的别名.操作符)将库文件中的函数添加到.bashrc脚本中。 shell还会将定义好的函数传给子shell进程,这样一来,这些函数就自动能够用于该shell会话中的任何shell脚本了。