文章说明
文章作者:鴻塵
文章链接:https://hwame.top/20210814/mongodb-aggregation-examples.html
参考资料:
- 聚合示例来源:Practical MongoDB Aggregations(by Paul Done@TheDonester)
- Ebook源码:Github @pkdone
- MongoDB在线运行:MongoDB Web Shell
温馨提示:测试数据可直接复制,方便生成数据;运行结果以图片形式展示,可以「点击图片」或「将图片拖曳到新标签页」来查看大图,从而获取更佳的浏览体验。
对MongoDB中聚合操作的理解和熟悉,需要配合大量例子,Practical MongoDB Aggregations Book中提供了很多有助于理解的例子,但原文是英文版的且有一定概率无法访问,故在此记录下学习过程中对原文的翻译。
说明:本文仅作为聚合示例,由于篇幅限制,对于数据库的指定及索引的创建都进行删减,并且也不执行
explain。
1.基础
(1)TopN查询
您想在由人组成的集合中查询,以找到职业为工程师的三个最年轻的人,按年龄从小到大排序。
此示例是本文中唯一一个可以以完全使用MQL实现的示例,同时也作为MQL和聚合管道之间的一个有用比较。
测试数据如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43{
"person_id": "6392529400",
"firstname": "Elise", "lastname": "Smith",
"dateofbirth": ISODate("1972-01-13T09:32:07Z"),
"vocation": "ENGINEER",
"address": { "number": 5625, "street": "Tipa Circle", "city": "Wojzinmoj"},
},
{
"person_id": "1723338115",
"firstname": "Olive", "lastname": "Ranieri",
"dateofbirth": ISODate("1985-05-12T23:14:30Z"),
"gender": "FEMALE",
"vocation": "ENGINEER",
"address": { "number": 9303, "street": "Mele Circle", "city": "Tobihbo"},
},
{
"person_id": "8732762874",
"firstname": "Toni", "lastname": "Jones",
"dateofbirth": ISODate("1991-11-23T16:53:56Z"),
"vocation": "POLITICIAN",
"address": { "number": 1, "street": "High Street", "city": "Upper Abbeywoodington"}
},
{
"person_id": "7363629563",
"firstname": "Bert", "lastname": "Gooding",
"dateofbirth": ISODate("1941-04-07T22:11:52Z"),
"vocation": "FLORIST",
"address": { "number": 13, "street": "Upper Bold Road", "city": "Redringtonville"}
},
{
"person_id": "1029648329",
"firstname": "Sophie", "lastname": "Celements",
"dateofbirth": ISODate("1959-07-06T17:35:45Z"),
"vocation": "ENGINEER",
"address": { "number": 5, "street": "Innings Close", "city": "Basilbridge"}
},
{
"person_id": "7363626383",
"firstname": "Carl", "lastname": "Simmons",
"dateofbirth": ISODate("1998-12-26T13:13:55Z"),
"vocation": "ENGINEER",
"address": { "number": 187, "street": "Hillside Road", "city": "Kenningford"}
}
聚合管道定义如下:1
2
3
4
5
6var pipeline = [
{"$match": {"vocation": "ENGINEER",}},
{"$sort": {"dateofbirth": -1,}},
{"$limit": 3},
{"$unset": ["_id", "vocation", "address",]},
];
执行聚合操作后应该返回三个文档,代表三个最年轻的工程师(按年龄从小到大排序),省略每个人的_id或address属性,如图所示:
Index Use. A basic aggregation pipeline, where if many records belong to the collection, a compound index for
vocation + dateofbirthshould exist to enable the database to fully optimise the execution of the pipeline combining the filter of the$matchstage with the sort from thesortstage and the limit of thelimitstage.Unset Use. An
$unsetstage is used rather than a$projectstage. This enables the pipeline to avoid being verbose. More importantly, it means the pipeline does not have to be modified if a new field appears in documents added in the future (for example, see thegenderfield that appears in only Olive’s record).MQL Similarity. For reference, the MQL equivalent for you to achieve the same result is shown below (you can try this in the Shell):
1 | db.persons.find( |
(2)分组汇总
您想要生成一份报告以显示每个客户在 2020 年购买的商品。
您将按客户对个人订单记录进行分组,捕获每个客户的「首单日期」、「订单数量」、「订单总价」和一个按日期排序的订单项目列表。
测试数据如下,orders集合由3个不同客户在2019-2021年间的9个订单组成:
1 | {"customer_id": "elise_smith@myemail.com", "orderdate": ISODate("2020-05-30T08:35:52Z"), "value": NumberDecimal("231.43")}, |
聚合管道定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20var pipeline = [
{"$match": {
"orderdate": {"$gte": ISODate("2020-01-01T00:00:00Z"), "$lt": ISODate("2021-01-01T00:00:00Z"), },
}},
// 按订单日期升序,需要选择下面的「first_purchase_date」
{"$sort": {"orderdate": 1, }},
{"$group": {
"_id": "$customer_id",
"first_purchase_date": {"$first": "$orderdate"},
"total_value": {"$sum": "$value"},
"total_orders": {"$sum": 1},
"orders": {"$push": {"orderdate": "$orderdate", "value": "$value"}},
}},
{"$sort": {"first_purchase_date": 1, }},
{"$set": {"customer_id": "$_id", }},
{"$unset": ["_id", ]},
];
执行聚合操作后应该返回代表三个客户的三个文档,文档分别包含了2020年首次购买日期、订单总价值、订单数量,以及订单详情列表。
Note, the order of fields shown for each document may vary.
Double Sort Use. It is necessary to perform a
$sorton the order date both before and after the$groupstage. The$sortbefore the$groupis required because the$groupstage uses a$firstgroup accumulator to capture just the first order’sorderdatevalue for each grouped customer. The$sortafter the$groupis required because the act of having just grouped on customer ID will mean that the records are no longer sorted by purchase date for the records coming out of the$groupstage.Renaming Group. Towards the end of the pipeline, you will see what is a typical pattern for pipelines that use
$group, consisting of a combination of$set+$unsetstages, to essentially take the group’s key (which is always called_id) and substitute it with a more meaningful name (customer_id).Lossless Decimals. You may notice the pipeline uses a
NumberDecimal()function to ensure the order amounts in the inserted records are using a lossless decimal type, IEEE 754 decimal128. In this example, if you use a JSON float or double type instead, the order totals will suffer from a loss of precision. For instance, for the customerelise_smith@myemail.com, if you use a double type, thetotal_valueresult will have the value shown in the second line below, rather than the first line:
1 | // 使用decimal128类型获得的期望结果 |
(3)解包数组及分组
您想要生成零售报告以列出已售出「昂贵产品」(价值超过 15 美元)的总价值和数量。
数据源是一个商店订单列表,其中每个订单都包含一个购买的产品集。
1 | { |
聚合管道定义如下:
1 | var pipeline = [ |
执行聚合操作后应该返回4个文档,代表客户订单中出现次数最多的4个仅有的「昂贵产品」,每个文档包括了产品的总订单价值和数量,如下所示:
Note, the order of fields shown for each document may vary.
Unwinding Arrays. The
$unwindstage is a powerful concept, although often unfamiliar to many developers initially. Distilled down, it does one simple thing: it generates a new record for each element in an array field of every input document. If a source collection has 3 documents and each document contains an array of 4 elements, then performing an$unwindon each record’s array field produces 12 records (3 x 4).Introducing A Partial Match. The current example pipeline scans all documents in the collection and then filters out unpacked products where
price > 15.00. If the pipeline executed this filter as the first stage, it would incorrectly produce some result product records with a value of 15 dollars or less. This would be the case for an order composed of both inexpensive and expensive products. However, you can still improve the pipeline by including an additional “partial match” filter at the start of the pipeline for products valued at over 15 dollars. The aggregation could leverage an index (onproducts.price), resulting in a partial rather than full collection scan. This extra filter stage is beneficial if the input data set is large and many customer orders are for inexpensive items only. This approach is described in the chapter Pipeline Performance Considerations.
(4)列表去重
您想在persons集合中查询,其中每个文档都包含其所说的一种或多种语言。
查询结果应该是按字母顺序排序的去重的语言列表,开发人员随后可以使用它来填充用户界面下拉小部件中的值列表。
此示例等效于SQL中的
SELECT DISTINCT语句。
1 | {"firstname": "Elise", "lastname": "Smith", "vocation": "ENGINEER", "language": "English",}, |
聚合管道定义如下:1
2
3
4
5
6var pipeline = [
{"$unwind": {"path": "$language"}}, // 解包language字段,该字段为数组或单个值
{"$group": {"_id": "$language"}},
{"$sort": {"_id": 1}},
{"$set": {"language": "$_id", "_id": "$$REMOVE"}},
];
执行聚合操作后应该返回按字母序的7个文档,代表不同的7种语言,如下所示: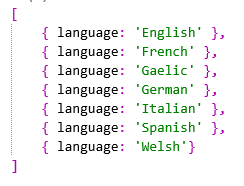
Unwinding Non-Arrays. In some of the example’s documents, the
languagefield is an array, whilst in others, the field is a simple string value. The$unwindstage can seamlessly deal with both field types and does not throw an error if it encounters a non-array value. Instead, if the field is not an array, the stage outputs a single record using the field’s string value in the same way it would if the field was an array containing just one element. If you are sure the field in every document will only ever be a simple field rather than an array, you can omit this first stage ($unwind) from the pipeline.Group ID Provides Unique Values. By grouping on a single field and not accumulating other fields such as total or count, the output of a
$groupstage is just every unique group’s ID, which in this case is every unique language.Unset Alternative. For the pipeline to be consistent with earlier examples in this book, it could have included an additional
$unsetstage to exclude the_idfield. However, partly to show another way, the example pipeline used here marks the_idfield for exclusion in the$setstage by being assigned the$$REMOVEvariable.
2.数据联结
(1)一对一联结
您想要生成一个报告来列出 2020 年所有的购买情况,显示每个订单的产品名称和类别,而不是产品ID。
为此您需要获取客户「订单集合
orders」,并将每个订单记录与「产品集合products」中的对应的产品相联结。两个集合之间存在「多对一
many:1」关系,因此在将订单与产品匹配时会产生「一对一1:1」的联结。联结将根据产品的id在双方之间使用单个字段比较。数据包括2019-2021年间的产品
products和订单orders两个集合,如下所示。
1 | // 集合products |
1 | // 集合orders |
聚合管道定义如下:
1 | var pipeline = [ |
执行聚合操作后应该返回代表2020年的3个订单文档,但每个订单的product_id字段替换成了两个新查找的字段product_name和product_category,如下所示。
Single Field Match. The pipeline includes a
$lookupjoin between a single field from each collection. For an illustration of performing a join based on two or more matching fields, see the Multi-Field Join & One-to-Many example.First Element Assumption. In this particular data model example, the join between the two collections is 1:1. Therefore the returned array of joined elements coming out of the
$lookupstage always contains precisely one array element. As a result, the pipeline extracts the data from this first array element only, using the$firstoperator. For an illustration of performing a 1:many join instead, see the Multi-Field Join & One-to-Many example.
(2)多字段联结及一对多
您想要生成一份报告,列出2020年每种产品所生成的所有订单。
为此,您需要将商店的「产品集合
products」中的每个产品product,与产品对应的订单order(订单位于orders集合)相联结。基于每侧两个字段的匹配,两个集合之间存在「一对多
1:many」的关系。联结需要使用两个公共字段(
product_name和product_variation),而不是像product_id(此数据集中不存在该字段)这样的单个字段。注意:执行一对多
1:many的联结并不强制要求在每一侧通过多个字段进行联结。然而在这个例子中,在一个地方展示这两个方面被认为是有益的。数据包括2019-2021年间的产品
products和订单orders两个集合,如下所示。
1 | // 集合products |
1 | // 集合orders |
聚合管道定义如下:
1 | var pipeline = [ |
执行聚合操作后应该返回2个文档,代表 2020 年有一个或多个订单的两个产品,每个产品对应的订单以数组形式展示,如下所示。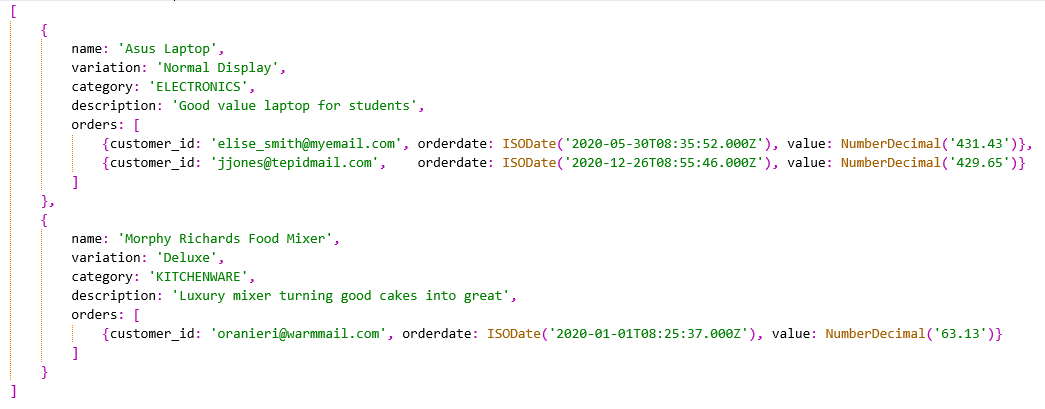
Multiple Join Fields. To perform a join of two or more fields between the two collections, you need to use a let parameter rather than specifying the
localFieldandforeignFieldparameters used in a single field join. With aletparameter, you bind multiple fields from the first collection into variables ready to be used in the joining process. You use an embeddedpipelineinside the$lookupstage to match the bind variables with fields in the second collection’s records. In this instance, because the$exproperator performs an equality comparison specifically (as opposed to a range comparison), the aggregation runtime can employ an appropriate index for this match.Reducing Array Content. The presence of an embedded pipeline in the
$lookupstage provides an opportunity to filter out three unwanted fields brought in from the second collection. Instead, you could use an$unsetstage later in the top-level pipeline to project out these unwanted array elements. If you need to perform more complex array content filtering rules, you can use the approach described in section 2. Avoid Unwinding & Regrouping Documents Just To Process Array Elements“ of the Pipeline Performance Considerations chapter.
3.数据类型转换
(1)强类型转换
一组零售订单retail orders已被某三方机构导入MongoDB集合中,但是所有数据类型都丢失了,因此所有字段值被存储为字符串形式。
您想为所有文档重新建立正确的数据,并将它们复制到一个新的「清理过的」集合中。您可以在聚合管道中包含该类型的转换逻辑,因为您知道每个字段在原始记录中的结构类型。
与本文中的大多数示例不同,聚合管道将其输出写入一个集合,而不是将结果流式地返回给调用的应用程序。
订单集合
orders包含三个订单文档,其中每个订单只有字符串形式的文本字段(注意,第二个文档有意缺少further_info子文档中的reported字段),如下所示。
1 | { |
聚合管道定义如下:
1 | var pipeline = [ |
执行聚合操作后将生成一个新的名为orders_typed的集合,新集合orders_typed应该与原集合orders具有相同数量的文档、相同的字段结构和字段名称,但现在使用了合适的强类型的布尔值、日期、整数和十进制值,集合内容如下所示。

Boolean Conversion. The pipeline’s conversions for integers, decimals, and dates are straightforward using the corresponding expression operators,
$toInt,$toDecimaland$toDate. However, the expression operator$toBoolis not used for the boolean conversion. This is because$toBoolwill convert any non-empty string to true regardless of its value. As a result, the pipeline uses a$switchoperator to compare the lowercase version of strings with the text'true'and'false', returning the matching boolean.Preserving Non-Existence. The field
further_info.reportedis an optional field in this scenario. The field may not always appear in a document, as illustrated by one of the three documents in the example. If a field is not present in a document, this potentially significant fact should never be lost. The pipeline includes additional logic for thefurther_info.reportedfield to preserve this information. The pipeline ensures the field is not included in the output document if it didn’t exist in the source document. A$ifNullconditional operator is used, which returns the$$REMOVEmarker flag if the field is missing, instructing the aggregation engine to omit it.Output To A Collection. The pipeline uses a
$mergestage to instruct the aggregation engine to write the output to a collection rather than returning a stream of results. For this example, the default settings for$mergeare sufficient. Each transformed record coming out of the aggregation pipeline becomes a new record in the target collection. The pipeline could have used a$outrather than a$mergestage. However, because$mergesupports both unsharded and sharded collections, whereas$outonly supports the former,$mergeprovides a more universally applicable example. If your aggregation needs to create a brand new unsharded collection,$outmay be a little faster because the aggregation will completely replace the existing collection if it exists. Using$merge, the system has to perform more checks for every record the aggregation inserts (even though, in this case, it will be to a new collection).Trickier Date Conversions. In this example, the date strings contain all the date parts required by the
$toDateoperator to perform a conversion correctly. In some situations, this may not be the case, and a date string may be missing some valuable information (e.g. which century a 2-character year string is for, such as the century19or21). To understand how to deal with these cases, see the Convert Incomplete Date Strings example chapter.
(2)残缺日期转换
应用程序正在将
payment文档提取到 MongoDB 集合中,其中每个文档的payment date字段都包含一个「看起来有点像日期时间」的字符串,例如"01-JAN-20 01.01.01.123000000"。您希望在聚合时将每个
payment date转换为有效的BSON日期类型,但是该字段不包含能准确确定确切日期时间所需的所有信息。因此,您不能直接使用 MongoDB 的日期表达式运算符将文本转换为日期。这些文本字段中的每一个都缺少以下信息:
- 明确的世纪:例如是1900s,还是2000s,还是其他;
- 明确的时区:例如是GMT,是IST,还是PST,还是其他;
- 三个字母的月份缩写所代表的具体语言:例如「JAN」是法语,还是英语,还是其他。
假设您随后了解到所有付款记录仅发生在21世纪,提取数据时使用的时区是UTC,使用的语言是英语。有了这些信息,您就可以构建一个聚合管道来将这些文本字段转换为日期字段。
缴费集合
payments包含12个支付文档,包括了时间乱序的覆盖了2020年所有12个月的数据,如下所示。
1 | {"account": "010101", "payment_date": "01-JAN-20 01.01.01.123000000", "amount": 1.01}, |
聚合管道定义如下:
1 | var pipeline = [ |
执行聚合操作后应该返回对应于原文档的12个文档,但将payment_date从文本值转换为正确的日期类型,如下所示。
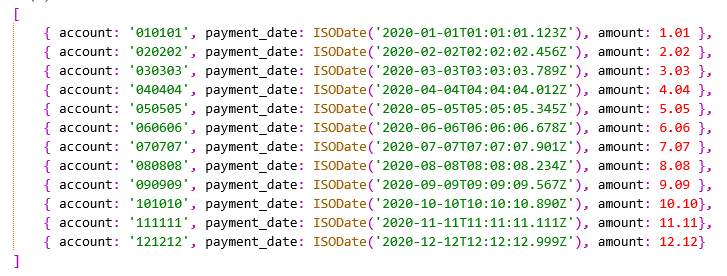
Concatenation Explanation. In this pipeline, the text fields (e.g.
'12-DEC-20 12.12.12.999000000') are each converted to date fields (e.g.2020-12-12T12:12:12.999Z). This is achieved by concatenating together the following four example elements before passing them to the$dateFromStringoperator to convert to a date type:'12-'(day of the month from the input string + the hyphen suffix already present in the text)'12'(replacing ‘DEC’)'-20'(hard-coded hyphen + hardcoded century)'20 12.12.12.999'(the rest of input string apart from the last 6 nanosecond digits)
Further Reading. This example is based on the output of the blog post: Converting Gnarly Date Strings to Proper Date Types Using a MongoDB Aggregation Pipeline.
4.趋势分析
(1)特征分类(分面检索)
您希望在零售网站上提供分面检索功能,使客户能够在网页中列出的产品结果中,通过选择指定特征来改善他们的产品搜索。
按不同维度对产品进行分类是有益的,其中每个维度(即「分面facet」)对应于产品记录中的特定字段(例如「产品评级」、「产品价格」)。每个分面都应分解为子范围,以便客户可以为特定分面(例如「评级」)选择特定的子范围(例如4~5星)。
聚合管道将根据每个分面的字段(
rating和price)来分析products集合,以确定每个分面的值的分布。产品集合
products包含如下16个文档。
1 | { |
聚合管道定义如下:
1 | var pipeline = [ |
执行聚合操作后应该返回一个单独的文档,文档包含 2 个分面(分别关闭by_price和关闭by_rating),每个分面显示「其值的子范围」以及「属于每个子范围的产品」,如下所示。
Multiple Pipelines. The
$facetstage doesn’t have to be employed for you to use the$bucketAutostage. In most faceted search scenarios, you will want to understand a collection by multiple dimensions at once (price & rating in this case). The$facetstage is convenient because it allows you to define various$bucketAutodimensions in one go in a single pipeline. Otherwise, a client application must invoke an aggregation multiple times, each using a new$bucketAutostage to process a different field. In fact, each section of a$facetstage is just a regular aggregation [sub-]pipeline, able to contain any type of stage (with a few specific documented exceptions) and may not even contain$bucketAutoor$bucketstages at all.Single Document Result. If the result of a
$facetbased aggregation is allowed to be multiple documents, this will cause a problem. The results will contain a mix of records originating from different facets but with no way of ascertaining the facet each result record belongs to. Consequently, when using$facet, a single document is always returned, containing top-level fields identifying each facet. Having only a single result record is not usually a problem. A typical requirement for faceted search is to return a small amount of grouped summary data about a collection rather than large amounts of raw data from the collection. Therefore the 16MB document size limit should not be an issue.Spread Of Ranges. In this example, each of the two employed bucketing facets uses a different granularity number scheme for spreading out the sub-ranges of values. You choose a numbering scheme based on what you know about the nature of the facet. For instance, most of the ratings values in the sample collection have scores bunched between late 3s and early 4s. If a numbering scheme is defined to reflect an even spread of ratings, most products will appear in the same sub-range bucket and some sub-ranges would contain no products (e.g. ratings 2 to 3 in this example). This wouldn’t provide website customers with much selectivity on product ratings.
(2)最大图网络
基于类似于 Twitter 的社交网络数据库,您的组织希望了解新营销活动的最佳目标。
您想要搜索「社交网络用户」的集合,其中每个用户记录文档都包含一个用户名和该用户的关注者。
您将执行一个聚合管道查询,遍历每个用户记录的
followed_by数组,从而确定哪个用户具有最大的 network reach ,即最广的朋友圈。请注意,为简洁起见,此示例仅使用了一个简单的数据模型。然而这不太可能是一个最佳数据模型,例如拥有很多粉丝的社交网络用户对于
$graphLookup的大规模使用,抑或是在分片环境中运行。有关此类问题的更多指导,请参阅Socialite。用户集合
users包含以下10个社交网络用户文档,可考虑加上一个索引db.users.createIndex({"name": 1})来帮助优化 图的遍历 。
1 | { "name": "Paul", "followed_by": [] }, |
聚合管道定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24var pipeline = [
// 对于每个用户,图遍历他们的followed_by数组
{"$graphLookup": {
"from": "users",
"startWith": "$followed_by",
"connectFromField": "followed_by",
"connectToField": "name",
"depthField": "depth",
"as": "extended_network",
}},
{"$set": {
// Count the extended connection reach
"network_reach": {"$size": "$extended_network"},
// Gather the list of the extended connections' names
"extended_connections": {
"$map": {"input": "$extended_network", "as": "connection","in": "$$connection.name"}
},
}},
{"$unset": ["_id", "followed_by", "extended_network",]},
{"$sort": {"network_reach": -1,}},
];
执行聚合操作后应该返回对应原来的10个源社交网络用户的10个文档,每个文档包括用户的 网络到达数network reach count 和 扩展连接名称extended connection names ,按网络覆盖面最广的用户排序,如下所示。
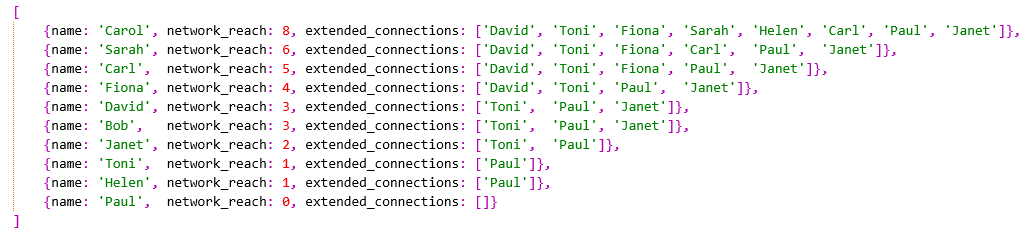
Following Graphs. The
$graphLookupstage helps you traverse relationships between records, looking for patterns that aren’t necessarily evident from looking at each record in isolation. In this example, by looking at Paul’s record in isolation, it is evident that Paul has no friends and thus has the lowest network reach. However, it is not obvious that Carol has the greatest network reach just by looking at the number of people Carol is directly followed by, which is two. David, for example, is followed by three people (one more than Carol). However, the executed aggregation pipeline can deduce that Carol has the most extensive network reach.Index Use. The
$graphLookupstage can leverage the index on the fieldnamefor each of itsconnectToFieldhops.
(3)增量分析
您有一组累积多年的 商店订单 ,零售渠道在每个交易日不断向
orders集合添加新订单记录。您希望经常生成汇总报告,以便管理层了解业务状态并对不断变化的业务趋势做出反应。多年来,生成所有每日总和和平均值的报告所需的时间越来越长,因为需要处理的数据天数越来越多。
从现在开始,为了解决这个问题,您将只在一天结束时生成当天的摘要分析,并将其存储在不同的集合中,该集合会随着时间的推移积累每日摘要记录。
与本文中的大多数示例不同,聚合管道将其输出写入一个集合,而不是将结果以流的形式传输回调用应用程序。
订单集合
orders包含9个文档,分别代表 2021-02-01 的 5 个订单和 2021-02-02 的 4 个订单,如下所示。
1 | {"orderdate": ISODate("2021-02-01T08:35:52Z"), "value": NumberDecimal("231.43"),}, |
定义一个函数来创建聚合管道,将「开始日期」和「结束日期」作为函数的参数,以便于在不同的日期多次执行聚合:
1 | function getDayAggPipeline(startDay, endDay) { |
仅对于 2021-02-01 的订单,调用上述getDayAggPipeline函数构建聚合管道,执行聚合后将结果写入汇总集合daily_orders_summary,查看汇总集合内容应该只有1条记录【仅生成了 2021-02-01 的单个订单摘要,其中包含当天的总价值和订单数量】。
1 | // 【第一天】 |
现在仅在第二天(即仅对于 2021-02-02 的订单),构建管道并执行聚合。从结果中,您可以看到这两天的订单摘要都存在(在第一天的基础上追加了第二天)。
1 | // 【第二天】 |
为了模拟组织偶尔需要追溯更正旧订单,回到第一天并添加新的「高价值」订单。然后仅在第一天(2021-02-01)重新运行聚合,以表明您可以安全正确地重新计算 仅一天 的摘要:
1 | // 回顾性地将订单添加到第一天(2021-02-01)以模拟「漏掉一单」 |
执行上述三个聚合操作后,汇总集合daily_orders_summary如图所示: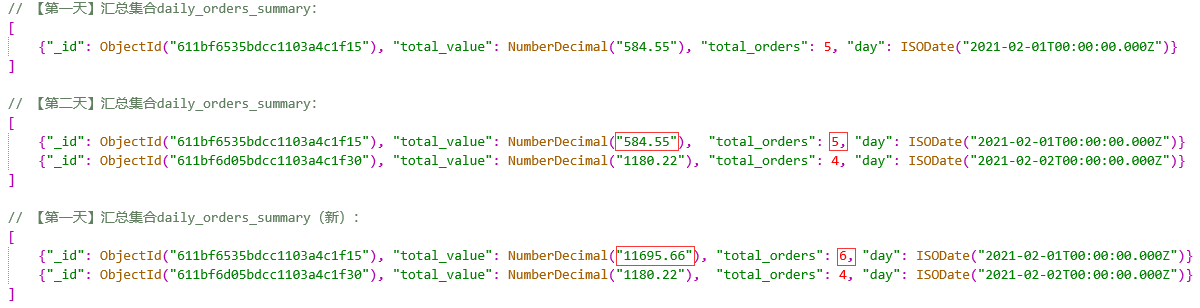
从结果中,您可以看到仍然存在两个订单摘要,两个交易日各一个,但第一天的总价值和订单数量发生了变化。如下图所示,当需要更正某天的订单摘要时,只要重新为那一天构建运行聚合管道即可修正。
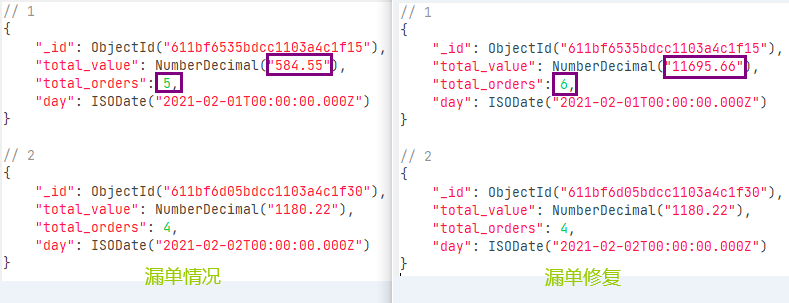
Merging Results. The pipeline uses a
$mergestage to instruct the aggregation engine to write the output to a collection rather than returning a stream of results. In this example, with the options you provide to$merge, the aggregation inserts a new record in the destination collection if a matching one doesn’t already exist. If a matching record already exists, it replaces the previous version.Incremental Updates. The example illustrates just two days of shop orders, albeit with only a few orders, to keep the example simple. At the end of each new trading day, you run the aggregation pipeline to generate the current day’s summary only. Even after the source collection has increased in size over many years, the time it takes you to bring the summary collection up to date again stays constant. In a real-world scenario, the business might expose a graphical chart showing the changing daily orders trend over the last rolling year. This charting dashboard is not burdened by the cost of periodically regenerating values for all days in the year. There could be hundreds of thousands of orders received per day for real-world retailers, especially large ones. A day’s summary may take many seconds to generate in that situation. Without an incremental analytics approach, if you need to generate a year’s worth of daily summaries every time, it would take hours to refresh the business dashboard.
Idempotency. If a retailer is aggregating tens of thousands of orders per day, then during end-of-day processing, it may choose to generate 24 hourly summary records rather than a single daily record. This provides the business with finer granularity to understand trends better. As with any software process, when generating hourly results into the summary collection, there is the risk of not fully completing if a system failure occurs. If an in-flight aggregation terminates abnormally, it may not have written all 24 summary collection records. The failure leaves the summary collection in an indeterminate and incomplete state for one of its days. However, this isn’t a problem because of the way the aggregation pipeline uses the
$mergestage. When an aggregation fails to complete, it can just be re-run. When re-run, it will regenerate all the results for the day, replacing existing summary records and filling in the missing ones. The aggregation pipeline is idempotent, and you can run it repeatedly without damaging the summary collection. The overall solution is self-healing and naturally tolerant of inadvertently aborted aggregation jobs.Retrospective Changes. Sometimes, an organisation may need to go back and correct records from the past, as illustrated in this example. For instance, a bank may need to fix a past payment record due to a settlement issue that only comes to light weeks later. With the approach used in this example, it is straightforward to re-execute the aggregation pipeline for a prior date, using the updated historical data. This will correctly update the specific day’s summary data only, to reflect the business’s current state.
5.数据安全
(1)严格视图
您有一个
persons集合,其中不应允许特定客户端应用程序查看敏感信息。因此,您将仅提供一个筛选后的人员数据子集的只读视图。在实际情况中,您还可以使用 MongoDB 的基于角色的访问控制(Role-Based Access Control,RBAC)来限制客户端应用程序只能访问视图而不是原始集合。
您将使用
adults视图以两种方式限制客户端应用程序的个人数据:
- 仅显示 18 岁及以上的人(通过检查每个人的
dateofbirth字段);- 从结果中排除每个人的
social_security_num字段。本质上,这是对 MongoDB 中实现「记录级(record-level)」访问控制的一个说明。
persons集合包含5条记录,如下所示。
1 | { |
聚合管道定义如下:1
2
3
4
5
6var pipeline = [
{"$match": {"$expr":{
"$lt": ["$dateofbirth", {"$subtract": ["$$NOW", 18*365.25*24*60*60*1000]}]
}}},
{"$unset": ["_id", "social_security_num"]},
];
首先,在创建视图之前执行聚合操作(并观察explain),以测试该定义的聚合管道。然后创建新的adults视图,它会在任何人查询视图时自动应用聚合管道。
1 | db.persons.aggregate(pipeline); |
对创建的视图执行常规 MQL 查询,没有任何过滤条件,并观察其explain;或者创建的视图执行 MQL 查询,指定过滤器为仅返回女性成年人,观察explain注意性别过滤器gender是如何影响它的。
1 | // 常规MQL查询 |
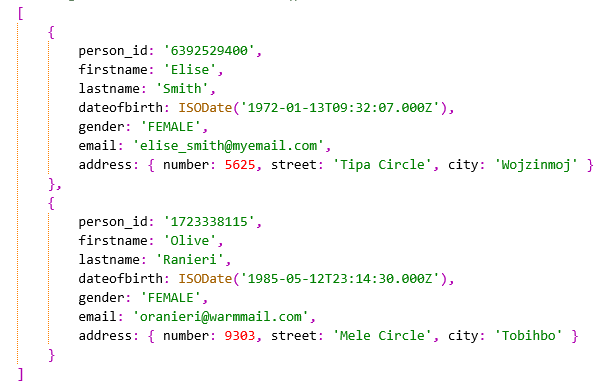
对于aggregate()和find()命令在 视图 上执行的结果应该是一样的,都返回3个文档,表示超过18岁的3个人,但是没有显示他们实际的出生日期,如图所示:

带有"gender": "FEMALE"过滤器的find()命令在 视图 上运行的结果应该仅有2条 女性 记录,因为男性记录已被排除,如下所示:
Expr & Indexes. The “NOW” system variable used here returns the current system date-time. However, you can only access this system variable via an aggregation expression and not directly via the regular MongoDB query syntax used by MQL and
$match. You must wrap an expression using$$NOWinside an$exproperator. As described in the section Restrictions When Using Expressions in an earlier chapter, if you use an $expr query operator to perform a range comparison, you can’t make use of an index in versions of MongoDB earlier then 5.0. Therefore, in this example, unless you use MongoDB 5.0, the aggregation will not take advantage of an index ondateofbirth. For a view, because you specify the pipeline earlier than it is ever run, you cannot obtain the current date-time at runtime by other means.View Finds & Indexes. Even for versions of MongoDB before 5.0, the explain plan for the gender query run against the view shows an index has been used (the index defined for the
genderfield). At runtime, a view is essentially just an aggregation pipeline defined “ahead of time”. Whendb.adults.find({"gender": "FEMALE"})is executed, the database engine dynamically appends a new$matchstage to the end of the pipeline for the gender match. It then optimises the pipeline by moving the new$matchstage to the pipeline’s start. Finally, it adds the filter extracted from the new$matchstage to the aggregation’s initial query, and hence it can then leverage an index containing thegenderfield. The following two excerpts, from an explain plan from a MongoDB version before 5.0, illustrate how the filter ongenderand the filter ondateofbirthcombine at runtime and how the index forgenderis used to avoid a full collection scan:1
2
3
4
5
6
7
8
9
10
11
12'$cursor': {
queryPlanner: {
plannerVersion: 1,
namespace: 'book-restricted-view.persons',
indexFilterSet: false,
parsedQuery: {
'$and': [
{ gender: { '$eq': 'FEMALE' } },
{ '$expr': { '$lt': [ '$dateofbirth',
{
'$subtract': [ '$$NOW', { '$const': 568036800000 } ]
...1
2
3
4
5
6
7inputStage: {
stage: 'IXSCAN',
keyPattern: { gender: 1 },
indexName: 'gender_1',
direction: 'forward',
indexBounds: { gender: [ '["FEMALE", "FEMALE"]' ] }
}In MongoDB 5.0, the explain plan will show the aggregation runtime executing the pipeline more optimally by entirely using the compound index based on both the fields
genderanddateofbirth.Further Reading. The ability for find operations on a view to automatically push filters into the view’s aggregation pipeline, and then be further optimised, is described in the blog post: Is Querying A MongoDB View Optimised?
(2)隐藏敏感字段
由于使用$rand运算符,要求MongoDB版本最低为 4.4。
您想对 信用卡付款 集合的敏感字段执行不可逆屏蔽,准备将输出数据集提供给第 3 方进行分析,而不会将敏感信息暴露给第 3 方。
您需要对付款字段进行的具体更改是:
- 部分混淆持卡人姓名;
- 混淆卡号的前 12 位数字,只保留最后 4 位数字;
- 通过添加或减去最多 30 天(约 1 个月)的随机金额来调整卡的到期时间;
- 用一组随机的 3 位数字替换卡的 3 位安全码;
- 通过添加或减去最多为原始金额 10% 的随机金额来调整交易金额;
- 将大约 20% 的记录中
reported字段的布尔值更改为相反值;- 如果嵌套子文档
customer_info的category字段为RESTRICTED,则排除整个子文档customer_info。
payments集合包含2条信用卡付款记录的文档,其中包含敏感数据,如下所示。
1 | { |
聚合管道定义如下:
1 | var pipeline = [ |
执行聚合操作后应该返回与源文档对应的2个文档,但它们的许多字段都被编辑和混淆了,并且标记为RESTRICTED的customer_info字段被省略了,如下所示。
Targeted Redaction. The pipeline uses a
$condoperator to return the$$REMOVEmarker variable if thecategoryfield is equal toRESTRICTED. This informs the aggregation engine to exclude the wholecustomer_infosub-document from the stage’s output for the record. Alternatively, the pipeline could have used a$redactstage to achieve the same. However,$redacttypically has to perform more processing work due to needing to check every field in the document. Hence, if a pipeline is only to redact out one specific sub-document, use the approach outlined in this example.Regular Expression. For masking the
card_namefield, a regular expression operator is used to extract the last word of the field’s original value.$regexFindreturns metadata into the stage’s output records, indicating if the match succeeded and what the matched value is. Therefore, an additional$setstage is required later in the pipeline to extract the actual matched word from this metadata and prefix it with some hard-coded text.Meaningful Insight. Even though the pipeline is irreversibly obfuscating fields, it doesn’t mean that the masked data is useless for performing analytics to gain insight. The pipeline masks some fields by fluctuating the original values by a small but limited random percentage (e.g.
card_expiry,transaction_amount), rather than replacing them with completely random values (e.g.card_sec_code). In such cases, if the input data set is sufficiently large, then minor variances will be equalled out. For the fields that are only varied slightly, users can derive similar trends and patterns from analysing the masked data as they would the original data.Further Reading. This example is based on the output of two blog posts: 1) MongoDB Irreversible Data Masking, and 2) MongoDB Reversible Data Masking.
6.时间序列
(1)IOT电力消耗
由于使用时间序列集合、$setWindowFields阶段和$integral运算符,要求MongoDB版本最低为 5.0。
您正在监控工业园区两栋建筑中运行的各种空调机组。每 30 分钟,每个机组中的一个设备将该机组当前的功耗读数发送回基地,中央数据库将保留该读数。
您想分析此数据,以查看每个空调机组在过去一小时内针对收到的每个读数所消耗的能量(以千瓦时 (kWh) 为单位)。此外,您还想计算每个建筑物中所有空调机组每小时消耗的总能量。
首先创建一个
device_readings集合,包含了两栋不同建筑物一天内的3个小时之间的设备读数,使用「时间序列集合」进行优化处理:
2
3
{"timeseries": {"timeField": "timestamp", "metaField": "deviceID", "granularity": "minutes"}}
);
注意,这个命令可以被注释掉,完整的例子仍然有效。device_readings集合的18条数据如下,分别为ABC和XYZ两栋建筑物的111、222和666三台设备在11:29am、11:59am、12:29pm、12:59pm、13:29pm、13:59pm的三个小时6个时段的电表读数。
1 | { |
为了计算空调机组在过去一小时内针对收到的每个读数所消耗的能量,定义一个「原始读数」的聚合管道如下:
1 | var pipelineRawReadings = [ |
为了计算每个建筑物中所有空调机组每小时消耗的总能量,定义一个「建筑物概要」的聚合管道如下:
1 | var pipelineBuildingsSummary = [ |
执行「原始读数」的聚合管道pipelineRawReadings,来计算空调机组在过去一小时内针对收到的每个读数所消耗的能量,返回的结果如下所示(简洁起见,省略_id字段):
执行「建筑物概要」的聚合管道pipelineBuildingsSummary,来计算每个建筑物中所有空调机组每小时消耗的总能量,返回的结果如下所示: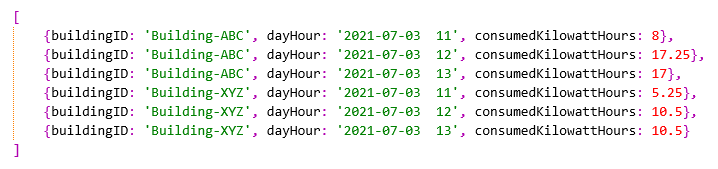
Integral Trapezoidal Rule. As documented in the MongoDB Manual,
$integral“returns an approximation for the mathematical integral value, which is calculated using the trapezoidal rule”. For non-mathematicians, this explanation may be hard to understand. You may find it easier to comprehend the behaviour of the$integraloperator by studying the illustration below and the explanation that follows: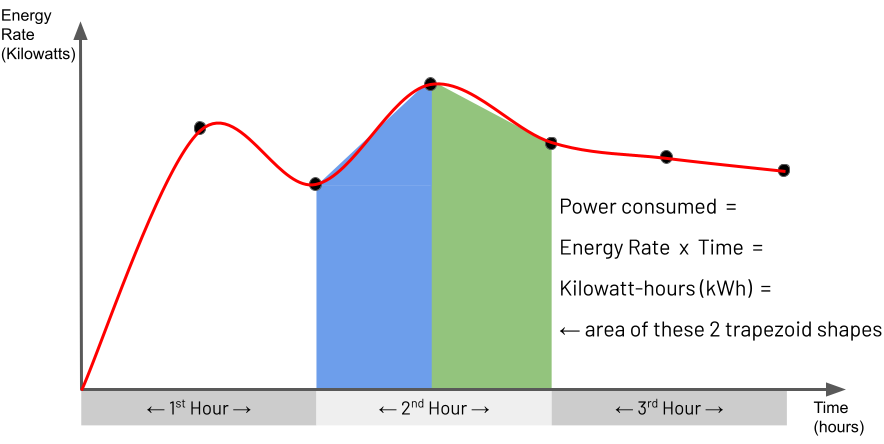
Essentially the trapezoidal rule determines the area of a region between two points under a graph by matching the region with a trapezoid shape that approximately fits this region and then calculating the area of this trapezoid. You can see a set of points on the illustrated graph with the matched trapezoid shape underneath each pair of points. For this IOT Power Consumption example, the points on the graph represent an air-conditioning unit’s power readings captured every 30 minutes. The Y-axis is the power rate in Kilowatts, and the X-axis is time to indicate when the device captured each reading. Consequently, for this example, the energy consumed by the air-conditioning unit for a given hour’s span is the area of the hour’s specific section under the graph. This section’s area is approximately the area of the two trapezoids shown. Using the
$integraloperator for the window of time you define in the$setWindowFieldsstage, you are asking for this approximate area to be calculated, which is the Kilowatt-hours consumed by the air-conditioning unit in one hour.Window Range Definition. For every captured document representing a device reading, this example’s pipeline identifies a window of 1-hour of previous documents relative to this current document. The pipeline uses this set of documents as the input for the
$integraloperator. It defines this window range in the settingrange: [-1, "current"], unit: "hour". The pipeline assigns the output of the$integralcalculation to a new field calledconsumedKilowattHours.One Hour Range Vs Hours Output. The fact that the
$setWindowFieldsstage in the pipeline definesunit: "hour"in two places may appear redundant at face value. However, this is not the case, and each serves a different purpose. As described in the previous observation,unit: "hour"for the"window"option helps dictate the size of the window of the previous number of documents to analyse. However,unit: "hour"for the$integraloperator defines that the output should be in hours (“Kilowatt-hours” in this example), yielding the resultconsumedKilowattHours: 8.5for one of the processed device readings. However, if the pipeline defined this$integralparameter to be"unit": "minute"instead, which is perfectly valid, the output value would be510Kilowatt-minutes (i.e. 8.5 x 60 minutes).Optional Time Series Collection. This example uses a time series collection to store sequences of device measurements over time efficiently. Employing a time series collection is optional, as shown in the
NOTEJavascript comment in the example code. The aggregation pipeline does not need to be changed and achieves the same output if you use a regular collection instead. However, when dealing with large data sets, the aggregation will complete quicker by employing a time series collection.Index for Partition By & Sort By. In this example, you define the index
{deviceID: 1, timestamp: 1}to optimise the use of the combination of thepartitionByandsortByparameters in the$setWindowFieldsstage. This means that the aggregation runtime does not have to perform a slow in-memory sort based on these two fields, and it also avoids the pipeline stage memory limit of 100 MB. It is beneficial to use this index regardless of whether you employ a regular collection or adopt a time series collection.