摘要:开发Python爬虫程序捕获异常后,如何对try语句重试,同时还需要满足对爬取数据 不重不漏 的要求。
文章说明
文章说明:本文首发于2019-09-27@segmentfault,更新于2020-05-27@hwame.top。
另请参考:segmentfault:Python中try-except出错后如何从try出错地方继续执行?
另请参考:segmentfault:在python中处理错误时,在执行完except语句下的内容后是否有办法回跳到代码出错的地方继续执行
文章作者:如果我可以忘记
创建时间:2019-09-27
更新时间:2020-05-27
1.问题背景
最近在写一个爬虫程序,数据和页面很简单,没有乱七八糟的反爬措施,但是数据量很大(每页5条记录,共12w页,总记录达61w),因此会出现网络连接的问题。
本着学习的目的,不借助其他爬虫框架,仅使用必需的库,包括:
requests,http请求库;lxml,用于解析网页内容和结构;re,正则表达式的Python标准库,处理字符串;csv,将爬取的数据存入csv文件。
2.题目描述
🌹原始方案
1 | for n in range(2, pages + 1): |
这段代码对于少量数据的爬取可以完成,但是本次12w+的页面,没办法在网络断开后重试,因此需要改进。
🌹改进思路
为了使其完整爬取12w+的页面,需要使用try—except语句进行异常处理。
设想使其在 $[2, \; pages + 1]$ 中的某一页(如 $i=99$ )出错(即TimeOut连接超时)时,except捕获到这个异常,同时使程序能正确的重新爬取这一页( $i=99$ )。
思路1:
for循环包括整个try—except语句
2
3
4
5
6
7
for n in range(2, pages + 1):
try:
append_data_to_csv(filepath, n)
print("Page {} finished...".format(n))
except TimeoutError as err:
print("Page {0} failed: {1}".format(n, err))思路2:
for循环只在try子句中,函数function_restarting(start_point)中有一个for循环
2
3
4
5
6
7
8
9
10
11
12
def function_restarting(args):
for n in range(pages + 1):
parse_HTML()
append_data_to_csv()
start_point = 2
while start_point < numbers:
try:
function_restarting(start_point)
except TimeoutError as err:
print("\tCurrent page failed: {}".format(err))
3.问题描述
🌷思路1存在的问题
如上思路1所示,如果for循环包括了整个try—except语句,那么虽然可以继续循环,但是是从 $i=100$ 开始的, $i=99$ 被跳过了,这将导致爬取数据的缺失,不符合预期。
🌷思路2存在的问题
如上思路2所示,for循环只在try里面,从起始页(start_point = 2)开始,假设仍在第99页( $i=99$ )出错,控制台输出信息如下:1
2
3
4
5
6
7.............(省略).............
Page 98 collecting...............
Page 99 collecting...............
Current page failed: (省略TimeoutError具体信息)
Page 2 collecting...............
Page 3 collecting...............
.............(省略).............
报错打印错误信息后仍从start_point(= 2),相当于重新运行了整个程序,并没有继续从99开始,不符合预期。
🌷问题提炼
问题1:怎样让他重试一次 $i=99$ 而不是直接跳过?
问题2:Page 99失败后怎样继续Page 99而不是重新开始从Page 2运行?
4.解决方案
🍀思路及途径
✉ 如何将发生异常时的页码记录下来并可被使用呢?✉ 将try—except作为函数体、页码值作为返回值!
当
except语句捕获异常时,将此时的页码 $i$ 返回,将再将该返回值赋值给start_point,以此来更新起始页,从而避免思路2中的问题。完整的程序代码如下。
🍀完整代码
1 | import requests, re, csv, time |
5.后记
若直接使用爬虫框架,例如scrapy等,其对异常处理有完整的处理机制。
本文仅为学习之用,抱着学习的态度提供一种可行的思路。
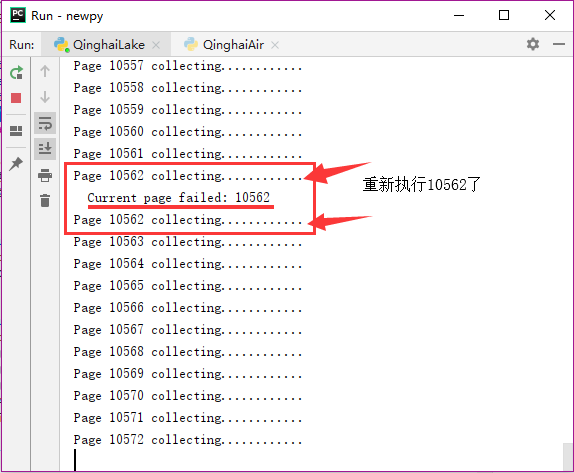
程序运行结果如下,当第10562页出错抛出异常时,能正确地重试,并使得程序继续运行。