摘要:史上最详细的Hadoop-Spark集群搭建采坑过程,包括VMware、Linux-CentOS-7、Java/JDK、Hadoop、Scala以及Spark的安装配置,图文并茂,每一个坑都填满。
文章说明
文章来源:本文由Word文件转换而来,因此保留了原始样式,字体为宋体+Times New Roman+Consolas。
文章说明:史上最详细的Hadoop集群搭建过程,包括VMware、Linux-CentOS-7、Java/JDK、Hadoop、Scala,以及Spark。原文共87页,字数共12497,合计29460字符,13章,段落数865,行数1335行,图片共113张。本文源码MarkDown文件字数共计47w+字符,行数2235行。
更新说明:(1)原文创建于2019-12-24,更新于2020-05-22,由于时间较久,其中CentOS-7已无1908版;(2)物理机安装环境为Windows 10 1503版,升级为Windows 10 1909版后无法使用VMware Workstation 15 Pro,应升级至15.5+,安装包和注册机网盘链接为【天翼云盘,点我下载】;(3)图片足有113张,加载速度较慢,请耐心等待~~
文章作者:鴻塵
1.概述
1.1.软件环境
1. 软件环境:VMware Workstation 15 Pro;
2. 虚拟机操作系统(清华大学开源软件镜像站-CentOS7下载),下载链接地址:https://mirrors.tuna.tsinghua.edu.cn/centos/7/isos/x86_64/CentOS-7-x86_64-Minimal-1908.iso
| 名称 | 系统及文件名 |
| master | CentOS-7-x86_64-Minimal-1908.iso |
| slave1 | CentOS-7-x86_64-Minimal-1908.iso |
| slave2 | CentOS-7-x86_64-Minimal-1908.iso |
3. 网络:我们实验室使用校园网有以下两种方法:
1.连接xxxx_WIRELESS,然后在弹出的网页中登陆;
2.插入网线,然后在弹出的网页中登陆。在这种情况下,如果安装的虚拟机需要联网,必须装桌面版,然后在自带的FireFox中登陆。

4. 虚拟网络采用NAT模式,详见后文。踩过的坑有很多,试过桥接模式,在Windows物理主机、Master、Slave1、Slave2四台机器之间互ping,不能保证相互ping通。
2.安装VMware Workstation
安装最新版的VMware Workstation 15 Pro,注意不能直接双击安装包,而要右键“以管理员方式运行”(因为安装过程中需要创建相关VMware服务,可能会有权限的问题)。
基本是傻瓜式安装,一路下一步即可。
文件名:VMware Workstation 15 Pro
网盘链接:https://pan.baidu.com/s/1G-Z4r2sLisuYwJbuHsmPPA,提取码:gf7q
许可证密钥:YG5H2-ANZ0H-M8ERY-TXZZZ-YKRV8
文件名:VMware-workstation-full-15.5.0-14665864
网盘链接:https://pan.baidu.com/s/1ObkjLqzlY5KbAUYMErQN4g,提取码:1314
许可证密钥:GF7TA-2VGD3-08EZZ-15XGG-X7KF2(若错误则需使用注册机KeyGen.exe激活,下载地址见顶部《文章说明》)
建议:1. 尽量不要安装在C盘,更改到其他盘符;2. 取消勾选“启动时检查产品更新”和“加入客户体验提升计划”;3. 显示“VMware Workstation Pro安装向导已完成”时不要点击“完成”,应该点击“许可证”,输入上面的许可证密钥后再点击“输入”。
3.网络配置准备工作
3.1.VMware设置
在VMware中点击“编辑” → “虚拟网络编辑器”,点击“更改设置”,如下图。
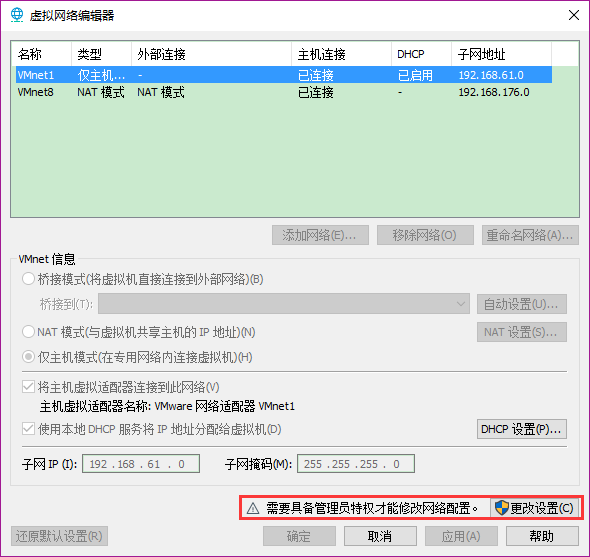
选择VMnet8(即NAT模式),如下图,点击“NAT设置”出现右图。其中,子网IP和子网掩码默认即可,网关IP将最后一位随意修改一下(与IP不同)。记住下图中的三个值:
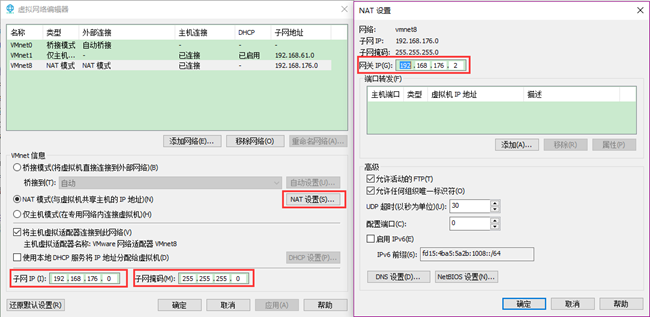
| 名称 | IP地址 | 备注 |
| 子网IP | 192.168.176.0 | 默认值 |
| 子网掩码 | 255.255.255.0 | 默认值 |
| 网关IP | 192.168.176.x | 修改x,此处的值为x=2 |
3.2.控制面板网络设置
3.2.1.查看网卡
打开控制面板 → 网络和共享中心 → 更改适配器设置,如下图。
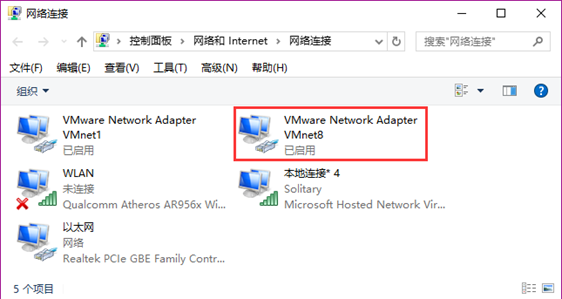
注1:之前安装的VMware版本为VM10,出现的不是“已启用”而是“未识别的网络”,通过安装最新版本VM15解决;
注2:可以发现,上图中没有VMnet0(桥接模式),这个问题应该是打开VMware时没有选择以管理员方式运行。
3.2.2.配置虚拟网卡VMnet8
双击VMnet8(NAT模式),点击“属性”,先选中“Internet协议版本4(TCP/IPv4”然后点击“属性”,选择“使用下面的IP地址”和“使用下面的DNS服务器地址”,如图所示。
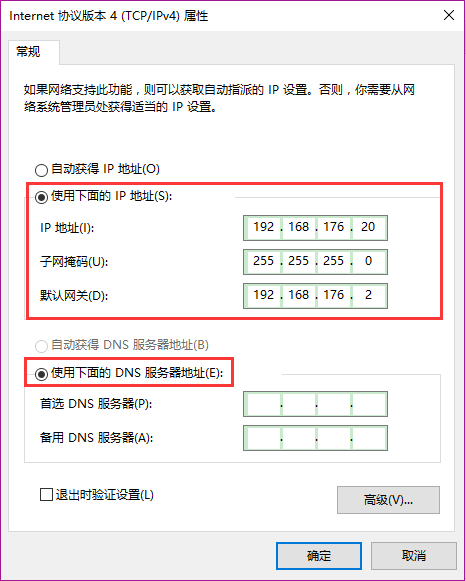
其中子网掩码和默认网关的地址和2.1节VMware设置中一致,但IP地址不和子网IP相同,比如我在这里设置为20。
3.3.查看物理主机信息
按“Windows键+R”输入“cmd”打开命令行,输入ipconfig /all,查看物理主机的Windows IP设置,如图所示。
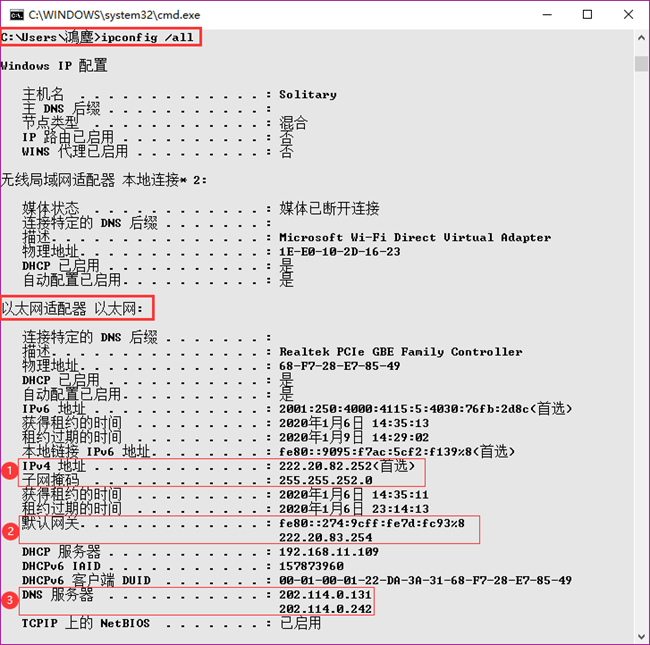
可以看到,物理主机信息和VMware默认的值很不一样。这是因为Windows物理机本身是处于校园网中,获得的IP地址也是自动分配的,如果使用WiFi连接登陆则IP又不一样。此处的IP是插入网线获得的,保证IP不变。
| Windows物理主机 | IP地址 | 备注 |
| IPv4地址 | 222.20.82.252 | 不同于VMware及VMnet |
| 子网掩码 | 255.255.252.0 | 不同于VMware及VMnet |
| 默认网关 | 222.20.83.254 | 不同于VMware及VMnet |
| DNS服务器1 | 202.114.0.131 | 默认值 |
| DNS服务器2 | 202.114.0.242 | 默认值 |
4.安装虚拟机
4.1.安装Master
4.1.1.说明
1. 必须在网络配置完成后才可进行接下来的步骤。
2. 为保证以下顺利进行,需要保证VMware服务已全部开启(VM15应该无需考虑),查看是否启动步骤:此电脑右键 → 管理 → 双击服务和应用程序 → 双击服务,确保VMware相关服务的状态为“正在运行”(至少保证①Authorization Service、②NAT Service、③Workstation Server三者正在运行),如下图。
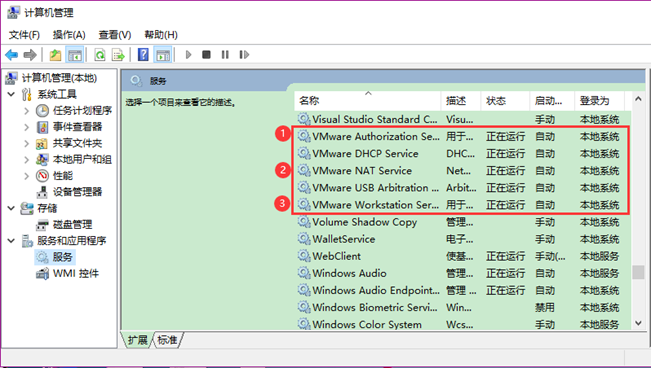
4.1.2.新建虚拟机
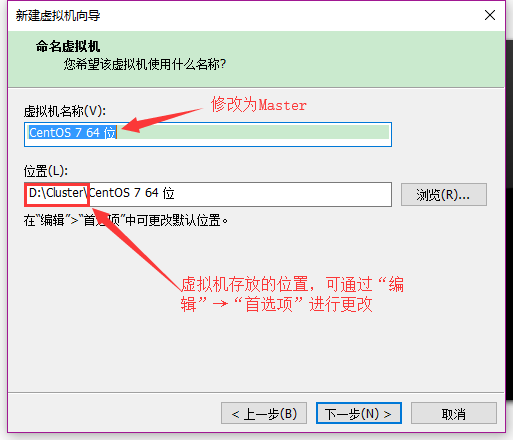
打开“新建虚拟机向导” → 选择自定义,下一步 → 硬件兼容性默认,下一步 → 选择“稍后安装操作系统”,下一步 → 操作系统选择Linux,版本选择CentOS 7 64位,下一步 → 修改虚拟机名称【默认位置可在“编辑” → “首选项”修改,默认C盘,也可手动指定,但必须先修改位置然后命名虚拟机名称】,如下图。
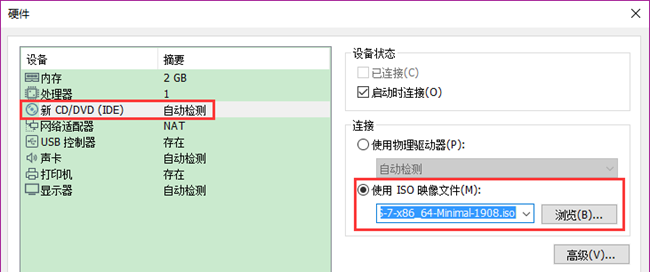
处理器配置默认即可 → 虚拟机内存选择2048MB(如果自己电脑内存小于8G,建议默认1024MB) → 网络类型选择“网络地址转换NAT”,下一步 → I/O控制器类型和磁盘类型默认 → 选择“创建新虚拟磁盘” → 磁盘大小默认20.0GB,选择“拆分成多个文件”(由于拆分成多个文件,因此实际不会使用到20.0GB) → 指定磁盘文件默认 → 点击“自定义硬件”弹出硬件窗口,在“硬件”窗口中点击“新CD/DVD(IDE)”选中使用ISO映像文件并选择下载好的CentOS-7-x86_64-Minimal-1908.iso文件(如图4.3所示),然后点击关闭,最后点击完成。
4.1.3.安装虚拟机
说明:因为我的集群已经搭建完成,下文以Tester为例。
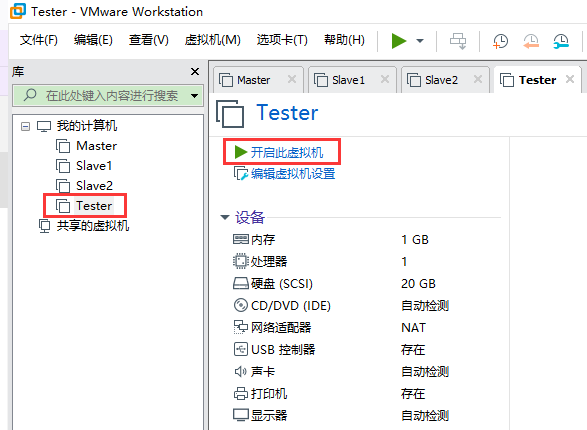
选中新建的虚拟机Tester,点击“开启此虚拟机”,如上图。进入安装界面,输入“chi”以筛选,然后选择中文,如下图。
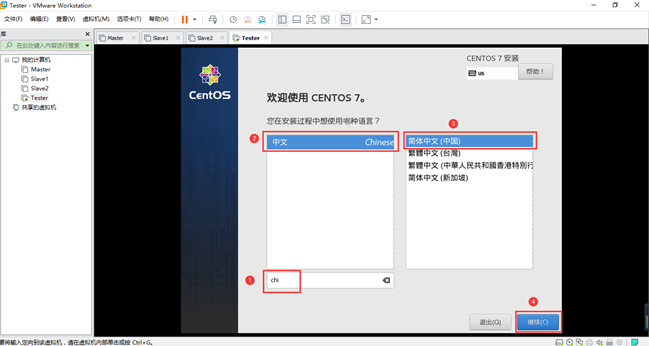
点击“安装位置”,无需更改,直接点击“完成”,然后点击“网络和主机名”,如下图。
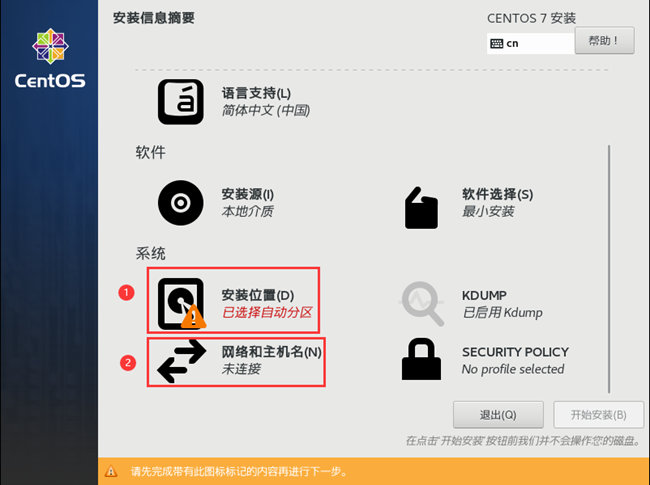
在弹出的“网络和主机名”中将主机名改为“master(此处以tester为例)”后点击“应用”,右边“当前主机名”会变为master(此处以tester为例),如图。
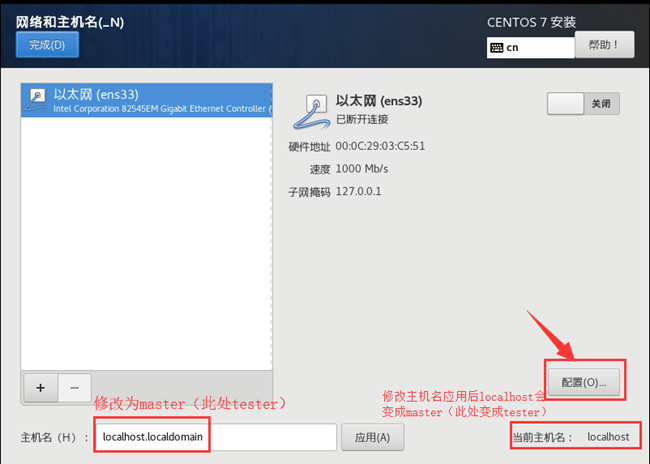
4.1.4.配置Master网络
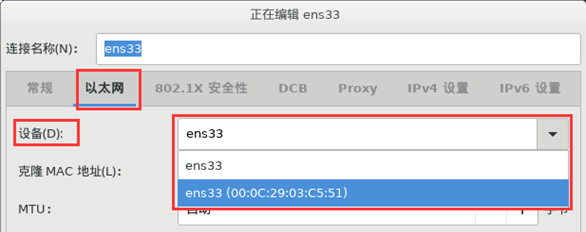
(1)修改主机名后,点击“配置”。在“以太网”选项卡中,将“设备”改为带有MAC地址的ens33(00:0C:29:03:C5:51),如下图所示。
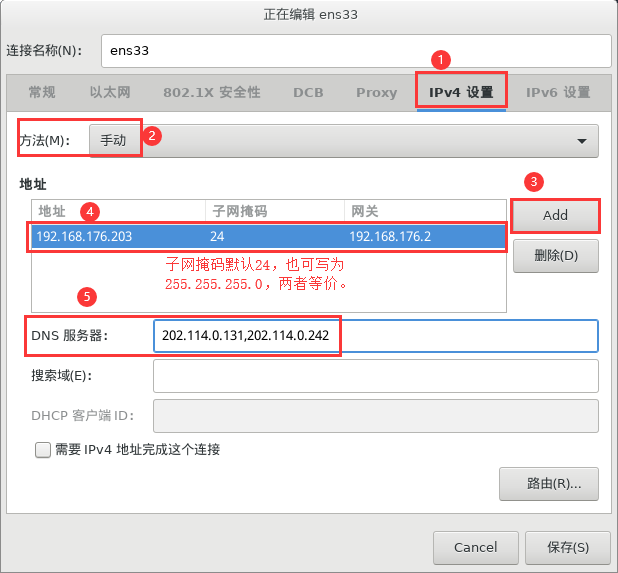
(2)在“IPv4设置”选项卡中,首先将方法修改为“手动”,然后点击“Add”添加地址和DNS服务器。其中,master的IP地址设置为192.168.172.200(以tester为例,此处设置的是192.168.176.203);子网掩码各节点相同(与VMware虚拟网络中的子网掩码一致),都是255.255.255.0,也可写为24,两种写法是等价的;DNS服务器地址有两个202.114.0.131和202.114.0.242,以英文逗号分隔,且无多余空格。
配置如下图所示。
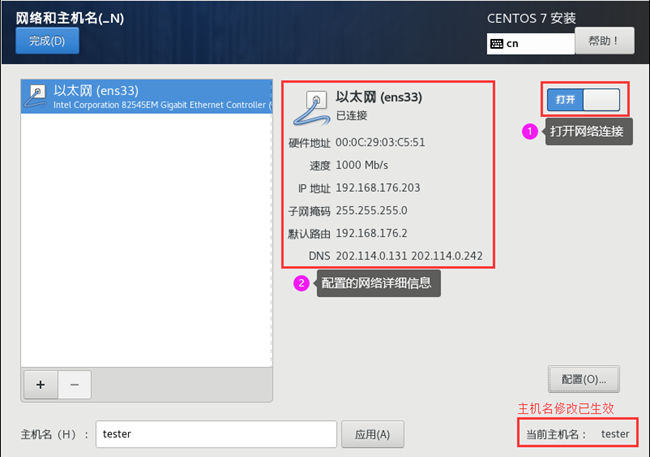
(3)在“IPv6设置”选项卡中,将方法改为“忽略”以禁用,配置完成点击“保存”。然后打开网络连接,可以看到配置生效,如图所示。
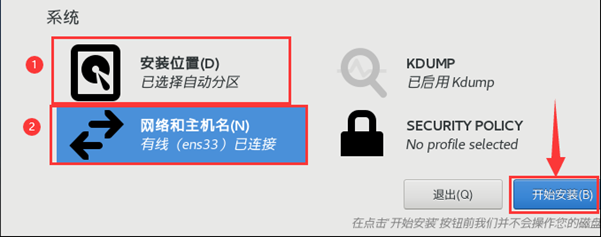
(4)最后在“网络和主机名”页面点击完成,可以看到所有安装信息均已完成,如图所示,最后点击“开始安装”。
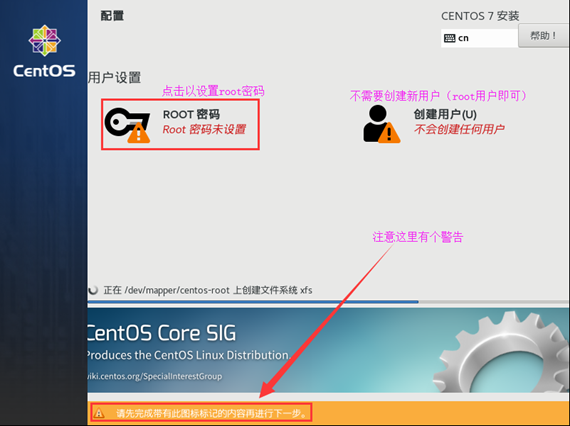
4.1.5.设置root密码
(1)由上开始安装后,界面如下图所示,此时必须设置root密码以完成带有警告图标的内容(只需要设置root密码,两处的标记即可正常)。
(2)点击设置root密码,如果密码强度太弱,则需要点击两次“完成”,如图所示。
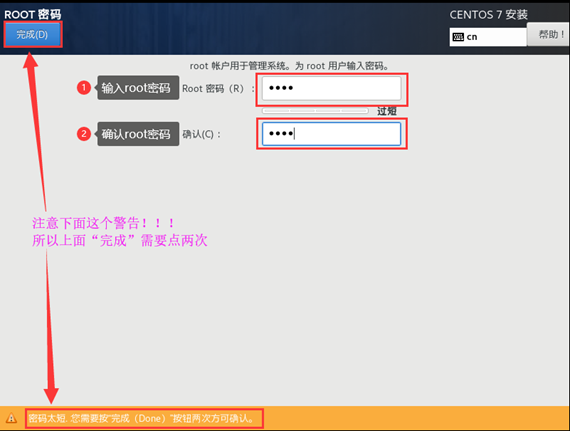
(3)完成root密码的设置,即使没有参加用户也不会有标记,点击“完成配置”,如图所示。
说明:在大数据集群搭建过程中,我们需要两个用户root和hadoop,目前只需要root管理员即可。

(4)点击“完成配置”后继续等待其他必要配置完成,最后点击重启,从而启动虚拟机master(此处为tester),如图所示。

4.2.安装Slave1
同4.1节,将虚拟机名称设置为“Slave1”,同时将主机名修改为“slave1”,且网络配置中slave1的IP地址设置为192.168.172.201。
4.3.安装Slave2
同4.1节,将虚拟机名称设置为“Slave2”,同时将主机名修改为“slave2”,且网络配置中slave2的IP地址设置为192.168.172.202。
至此,一主二次的虚拟机安装完成,如图所示(未删除测试机Tester)。
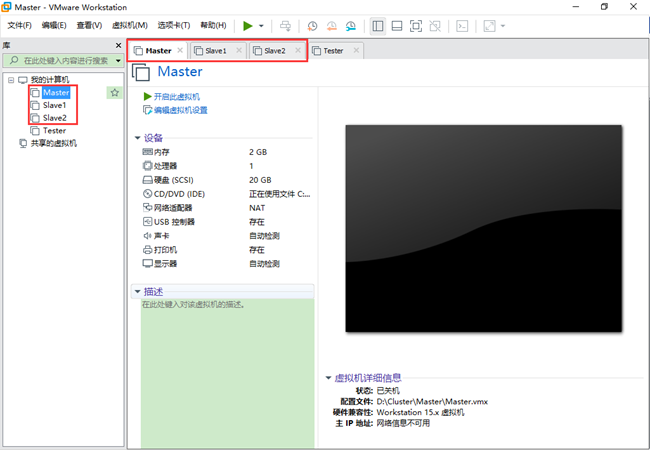
5.虚拟机配置
5.1.设置各节点名称
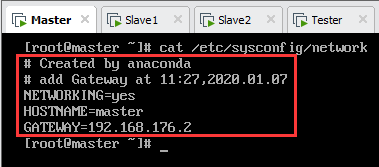
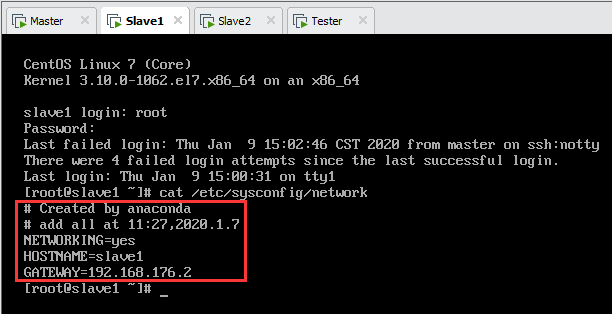
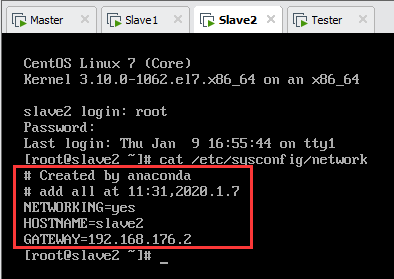
以Tester为例,输入并回车,按“I”键进入编辑模式。
NETWORKING=yes
HOSTNAME=master
GATEWAY=192.168.176.2
编辑完成后,按“Esc”键退出编辑模式,然后按“Shift+:”,最后输入“wq”(必须小写)并回车保存退出。
②内容编辑过,不保存强制退出,则输入“q!”;
③内容未编辑过,直接退出,则输入“q”。
设置完成后各节点名称如下图所示。
5.2.配置hosts
以Tester为例,配置hosts。
修改前原hosts文件内容为:
修改后的hosts文件内容为:
保存之后,在Master上将该文件分别拷贝至另外两个子节点,如图5.4所示。
输:[root@master ~]#scp /etc/hosts root@192.168.176.202:/etc/
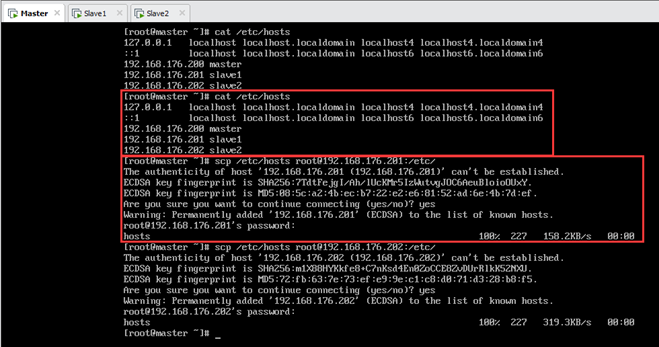
设置完成后各节点hosts文件都是一样的,如下图所示。
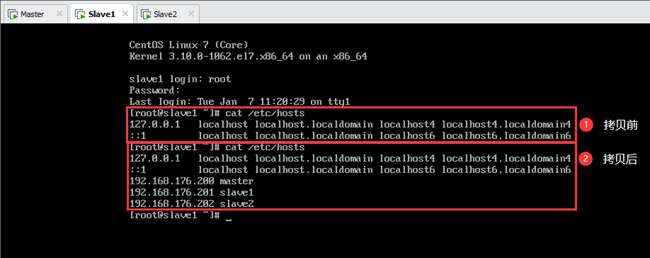
5.3.配置各节点网卡
以Tester为例,配置网卡ens33。由于在安装虚拟机的过程中已经基本配置好网络,因此只需要修改为静态IP即可(理论上,这一步也不需要,默认值是BOOTPROTO=”none”)。
查看原始网卡信息如图所示:
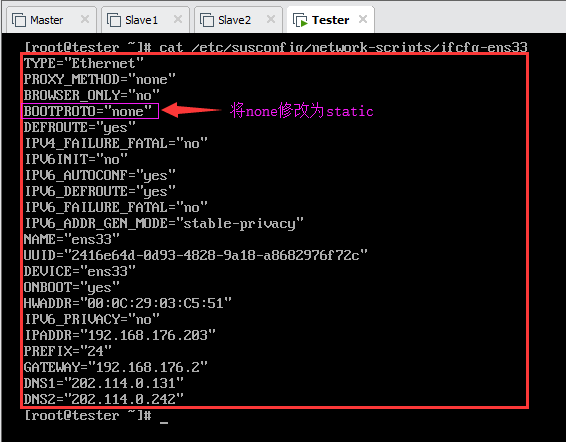
vi编辑此文件,将BOOTPROTO=”none”修改为BOOTPROTO=”static”,保存后重启网络:
5.4.关闭防火墙
5.4.1.以Tester为例
以Tester为例,首先查看防火墙状态(status),如图所示(默认状态为开启):
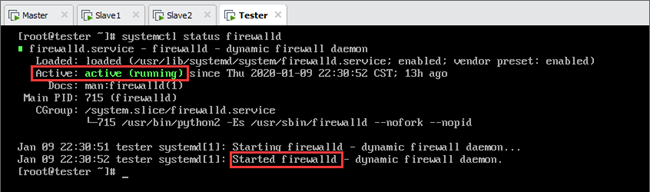
说明:我们需要禁用(永久关闭)防火墙,操作operation为“disable”;如果是临时关闭,则操作operation为“stop”;开启防火墙的操作operation为“start”。
禁用后需要重启网络并重启虚拟机(或者关闭<stop>防火墙即可,而不需要重启虚拟机)使之生效,再次查看状态,可以发现已经禁用,如图所示。
输:[root@tester ~]#systemctl restart network
输:[root@tester ~]#reboot(或者)systemctl stop firewalld
输:[root@tester ~]#systemctl status firewalld
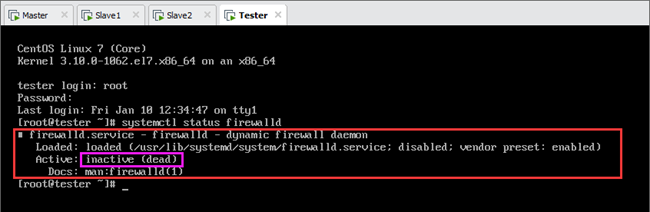
说明:该步骤分别在Master、Slave1和Slave2上进行,禁用所有节点的防火墙。
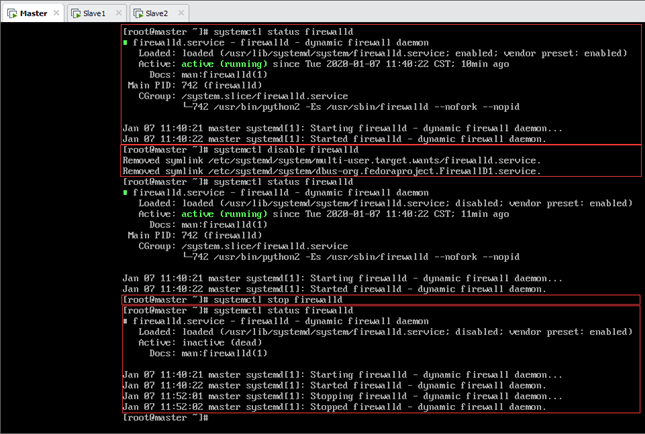
5.4.2.Master关闭防火墙截图
以Tester为例,首先查看防火墙状态(status)为active(running)(因为防火墙默认是开启的),然后禁用防火墙服务,此时防火墙依然是运行状态(因为在防火墙已经是开启的状态下禁用服务,只能影响下一次,所以需要重启生效或者手动关闭防火墙)。关闭(stop)防火墙后再次查看防火墙状态,可以看到其状态为inactive(dead)。如图所示:
5.5.互ping测试
5.5.1.Windows物理主机
打开cmd窗口,分别ping四台虚拟机(包括Tester),如图所示:
物理主机ping主节点Master:
物理主机ping从节点Slave1:
物理主机ping从节点Slave2:
物理主机ping测试机Tester:
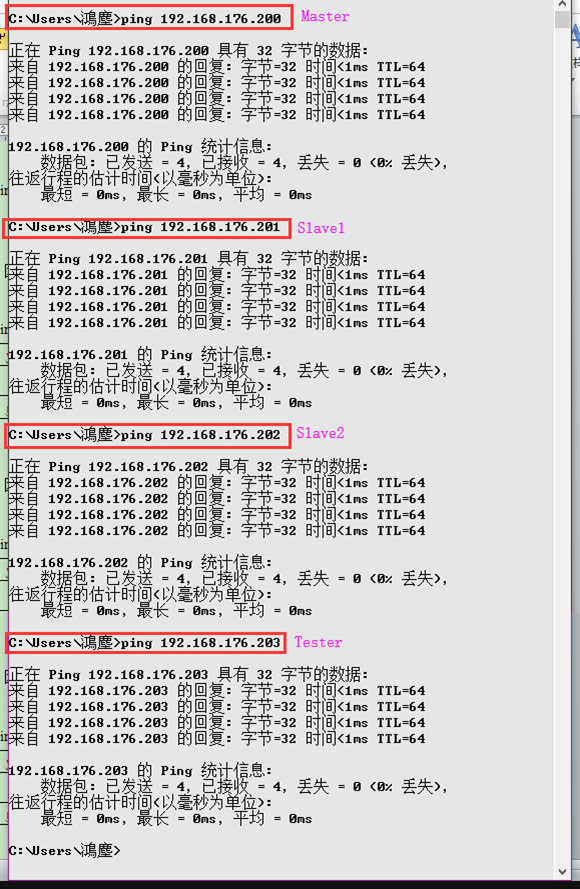
5.5.2.Mater虚拟机
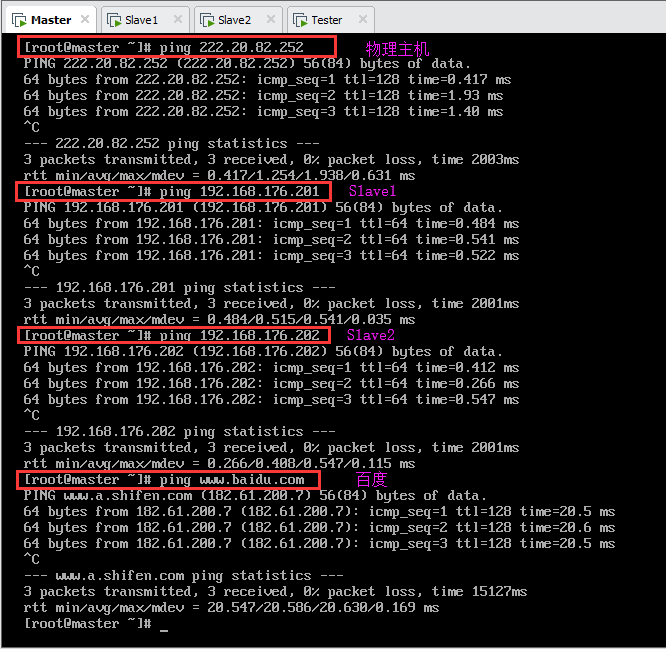
虚拟机Mater分别ping物理主机、虚拟机Slave1、虚拟机Slave2和测试机Tester(此处未截图,实际能ping通),以及外网(百度),如图所示:
5.5.3.Slave1虚拟机
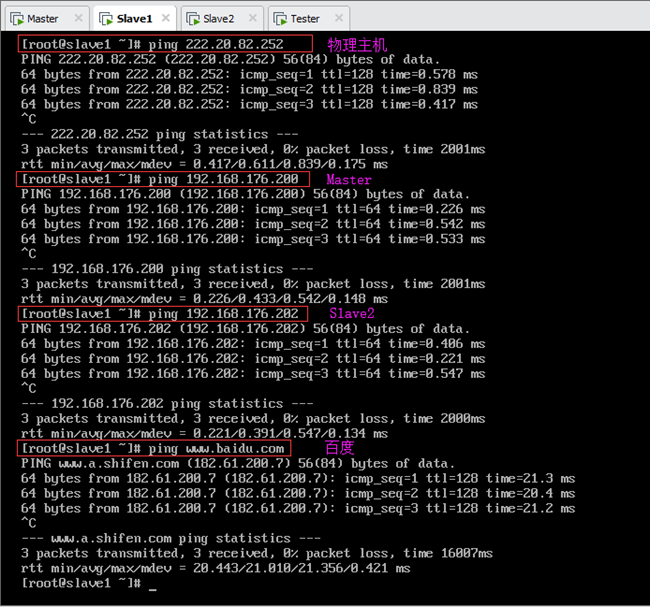
虚拟机Slave1分别ping物理主机、虚拟机Mater、虚拟机Slave2和测试机Tester(此处未截图,实际能ping通),以及外网(百度),如图所示:
5.5.4.Slave2虚拟机
虚拟机Slave2分别ping物理主机、虚拟机Mater、虚拟机Slave1和测试机Tester(此处未截图,实际能ping通),以及外网(百度),如图所示:
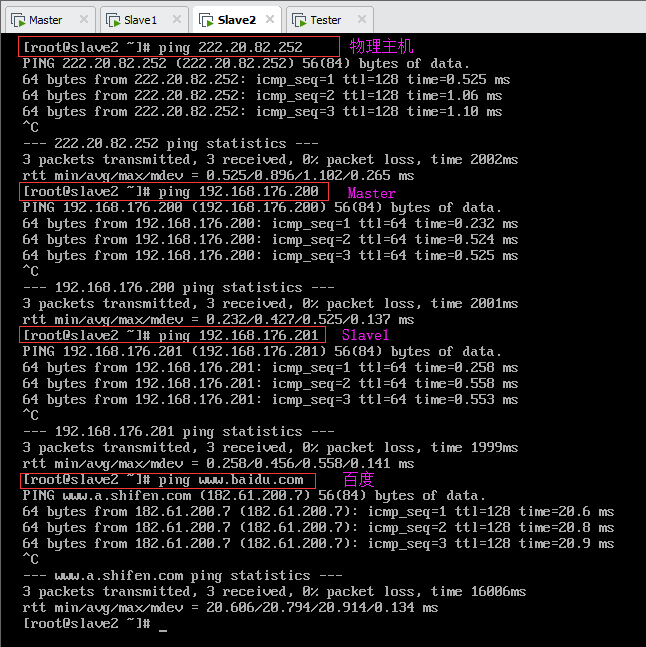
由上,集群内三台虚拟机可以相互通信,也可以和Windows物理主机相互通信,并且可访问外网。
6.JDK的安装与配置
由于Hadoop的编译及MapReduce的运行都需要使用JDK,所以需要在集群中的每一台机器上提前安装好能够满足Hadoop最低版本要求的JDK。
参考文章:https://blog.csdn.net/github_38336924/article/details/82221258
6.1.检查是否已安装JDK及卸载
测试机Tester未安装过Java,故以Tester为例。
检查是否已安装JDK(中括号选其一),如下图(图中没有输出信息即代表没有相关的安装文件):
查询已安装的包文件(中括号选其一),如下图(图中没有输出信息即代表没有相关的安装文件):
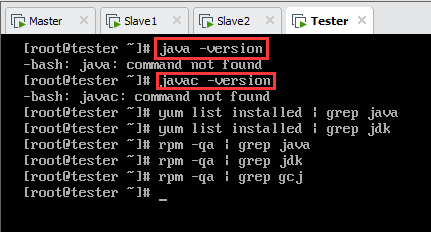
没有Java相关的文件,因此不需要卸载。安装过程省略。
6.2.Master安装JDK
6.2.1.查看JDK软件包列表
查看JDK软件包列表,如图所示:
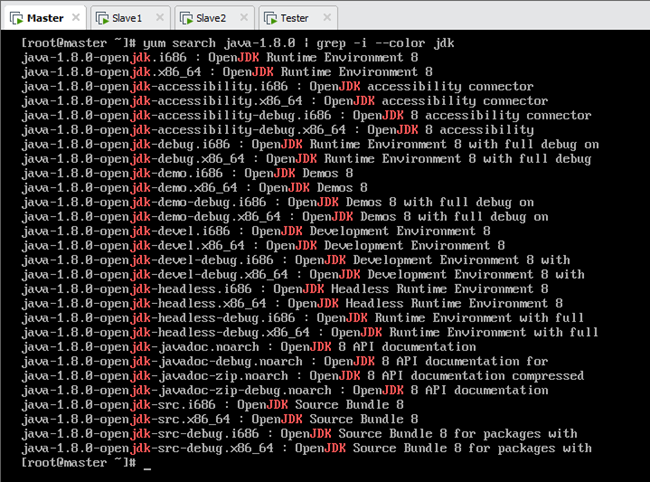
6.2.2安装openjdk
在上图JDK软件包列表中,不需要安装所有包,只需要安装其中java-1.8.0-openjdk和java-1.8.0-openjdk-devel即可,如图所示:
说明:yum选项加入“-y”是对所有的提问都回答“yes”,可以避免在安装过程中出现的反复确认,从而加快安装速度。java-1.8.0-openjdk和java-1.8.0-openjdk-devel两个包将被一起安装,同时所需的依赖也会被安装,如下图所示。
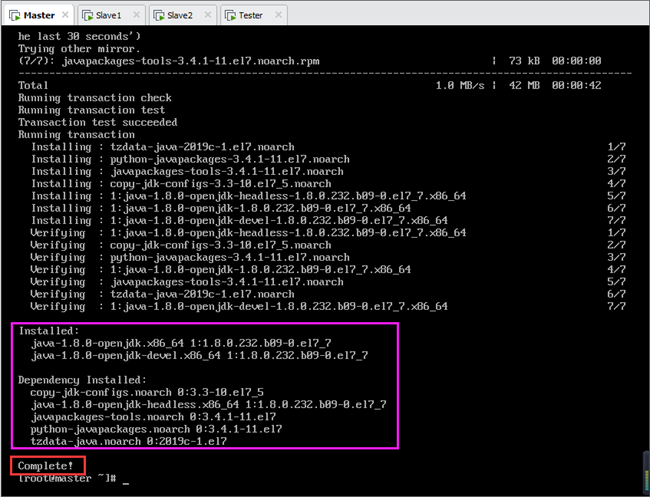
等待安装完成,可以看到java-1.8.0-openjdk和java-1.8.0-openjdk-devel已经安装,并且5个依赖包也一并被安装。
6.2.3.查看是否安装成功
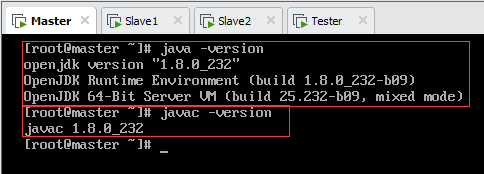
说明:yum方式安装JDK,其默认路径是/usr/lib/jvm,如图所示。
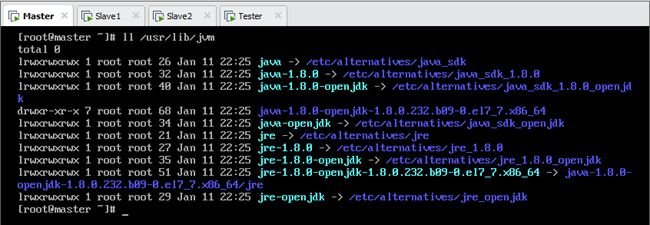
6.2.4.配置环境变量
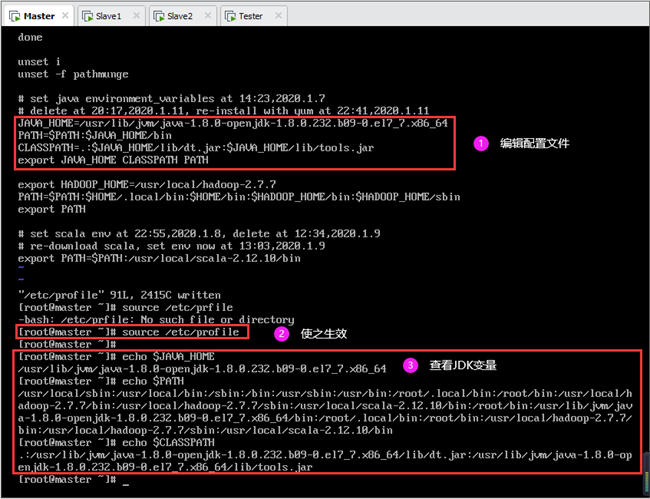
编辑/etc/profile文件
末尾处添加如下内容(文件中 # 代表注释):
使配置生效(也可重启虚拟机):
使用echo命令查看JDK变量:
设置完成后如图所示:
6.3.Slave1和Slave2安装JDK
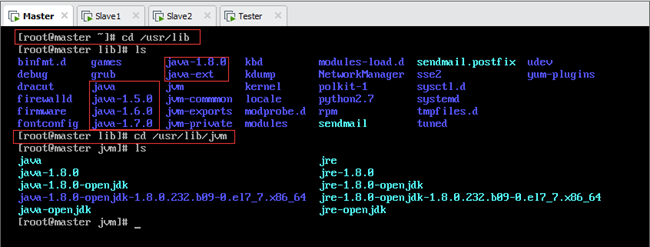
安装步骤和Master相同,也可将Master安装文件夹远程拷贝至Slave1和Slave2节点(不推荐,因为采用yum安装不仅仅在/usr/lib/jvm文件夹下,如图),按6.2节步骤即可。
7.配置SSH免密码登录
在 Hadoop 集群中的各个节点之间需要使用 SSH 频繁地进行通信,为了避免每次的通信都要求输入密码,需要对各个节点进行 SSH 免密码登录配置。
7.1.开启sshd密钥认证
在进行SSH免密码登录配置之前,需要先开启 sshd密钥认证。编辑每一台机器(以Tester为例)的 /etc/ssh/sshd_config 文件,去掉原文件下面这3行前的“#”注释。
②# PubkeyAuthentication yes
③# AuthorizedKeysFile.ssh/authorized_keys
注意:/etc/ssh/sshd_config文件内容如图所示,可以看到只有上述三行中的②③行,并没有①# RSAAuthentication yes。这是因为第1代ssh通讯协议使用的配置项RSA认证(RSAAuthentication)已废除,第2代ssh通讯协议的密钥验证是PubkeyAuthentication。而且第③行默认是开启的(如图第47行),故只需去掉上述第②行的注释(对应文件第43行,如图所示)。参考文章:https://www.cnblogs.com/Leroscox/p/9627809.html
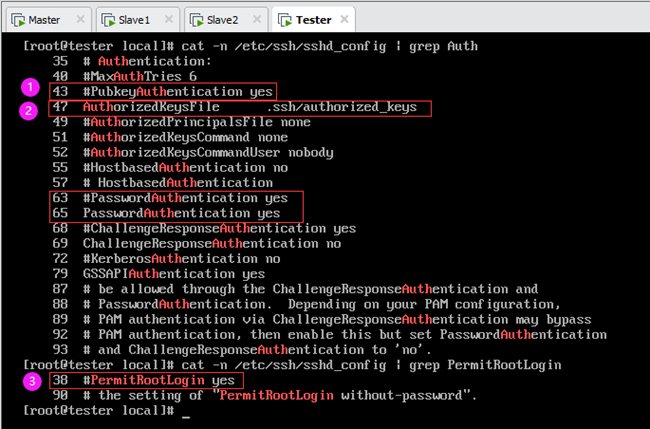
综上所述,编辑 /etc/ssh/sshd_config 文件,去掉第43行注释即可,如上图①处。另外,按上述文章,还应允许root认证登陆(PermitRootLogin),去掉第38行注释即可,如上图③处。
设置完成保存后,重启sshd服务:
注:每个节点都需要配置。
7.2.创建免密码登录账户
由于Hadoop 集群中的各节点默认会使用当前的账号SSH免密码登录其它节点,所以需要在每个节点中创建一个相同的供 Hadoop 集群专用的账户,我们使用的账户为 hadoop 。
注:每个节点都需要创建hadoop用户,至此每个节点拥有root和hadoop两个用户。
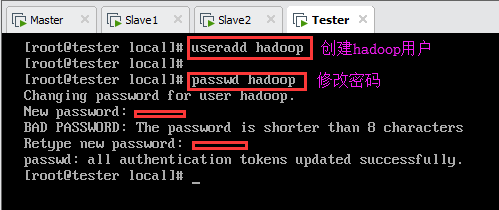
创建用户:
设置密码:
如图所示:
7.3.生成公钥密钥对
在每个节点上分别执行(以Tester为例):
首先切换到hadoop用户(注意提示符,# 表示root用户,$ 表示一般用户):
然后输入以下命令,根据提示按三次回车键直到生成结束,如图所示。
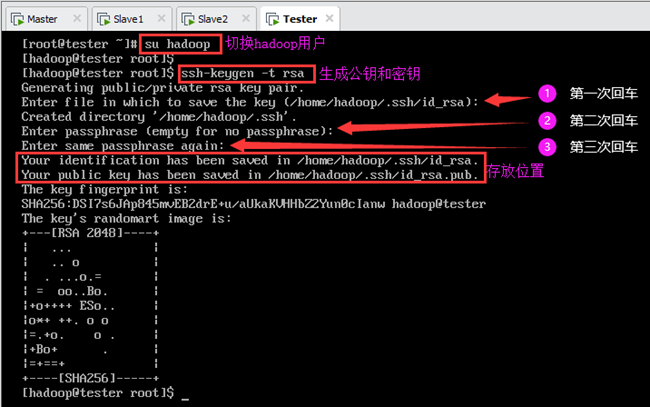
在Master、Slave1和Slave2三个节点上分别都执行上述步骤后(以hadoop用户身份),会在每个节点的/home/hadoop/.ssh目录下自动生成两个文件id_rsa和id_rsa.pub,其中前者为私钥,后者为公钥,如上图所示。
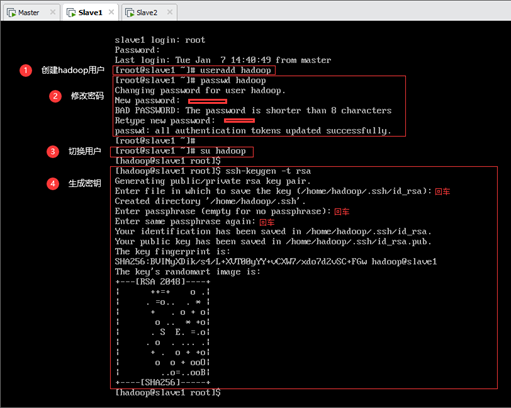
Slave1节点上生成公钥密钥对如下图所示。
Slave2节点上生成公钥密钥对如下图所示。

7.4.将公钥导入认证文件
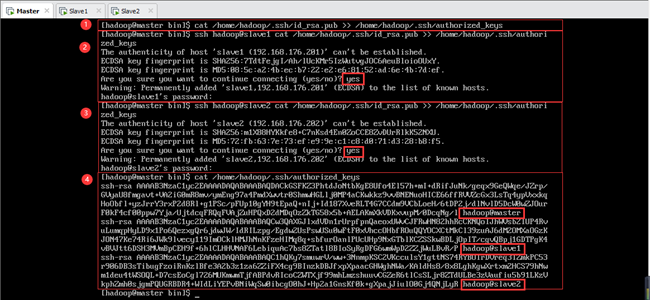
密钥生成之后,需要将每台机器的公钥都拷贝到主节点的认证文件 authorized_keys 中,以下操作都在主节点Master上由hadoop用户完成(如图7-6所示)。
①将Master的公钥导入主节点的认证文件中:
②将Slave1的公钥导入主节点的认证文件中(根据提示输入“yes”及密码):
③将Slave2的公钥导入主节点的认证文件中(根据提示输入“yes”及密码):
④各节点的公钥导入完成后,查看认证文件内容,可以看到各个节点的hadoop用户的公钥信息,如图7-6所示。
7.5.设置权限并补全Master信息
在 Master 主机上执行如下命令,对认证文件的操作权限进行设置,如图7.7所示:
输:[hadoop@master ~]$ chmod 600 /home/hadoop/.ssh/authorized_keys
查看known_hosts文件中主机列表,发现只有Slave1和Slave2而没有Master自身(如图7.7所示箭头处),所以需要在Master主机上ssh免密登录自己,将自身的主机信息添加到known_hosts列表中。
注意:登陆成功后的状态是以hadoop@master的身份ssh登陆hadoop@master,所以提示符都是[hadoop@master ~]$。登陆成功后即将其信息写入到known_hosts文件中(注意ssh登陆时的警告),所以还要输入exit退出远程登陆回到当前的hadoop@master身份。
退出后,再次查看known_hosts文件中,可以看到已成功将Master节点信息写入其主机列表中,如图所示。
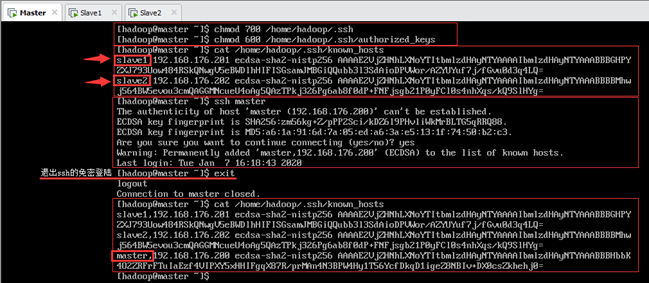
7.6.将认证文件复制到slave节点
在 Master 主机上执行以下命令将生成的 authorized_keys 文件从 Master 主机复制到 Slave1 和 Slave2 节点,如图7.8所示。
输:[hadoop@master ~]$ scp /home/hadoop/.ssh/authorized_keys hadoop@slave2:/home/hadoop/.ssh/authorized_keys
在 Master 主机上测试ssh远程登陆Slave1 和 Slave2 节点,如图7.8所示,可以发现不需要登陆密码了。
输:[hadoop@master ~]$ ssh slave2
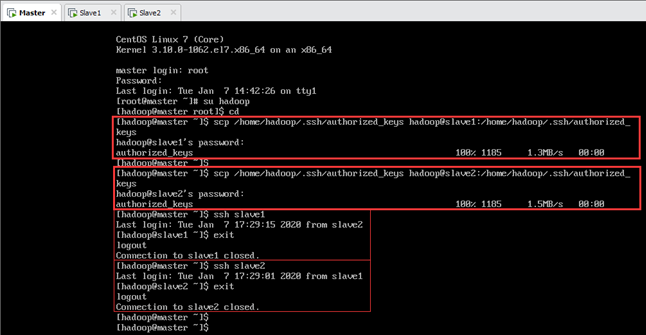
在 Master 主机上执行以下命令将生成的 known_hosts 文件从 Master 主机复制到 Slave1 和 Slave2 节点。
输:[hadoop@master ~]$ scp /home/hadoop/.ssh/ known_hosts hadoop@slave2:/home/hadoop/.ssh/known_hosts
7.7.设置从节点认证文件权限
设置从节点Slave1认证文件权限:
输:[hadoop@slave1 ~]$ chmod 600 /home/hadoop/.ssh/authorized_keys
设置从节点Slave2认证文件权限:
输:[hadoop@slave2 ~]$ chmod 600 /home/hadoop/.ssh/authorized_keys
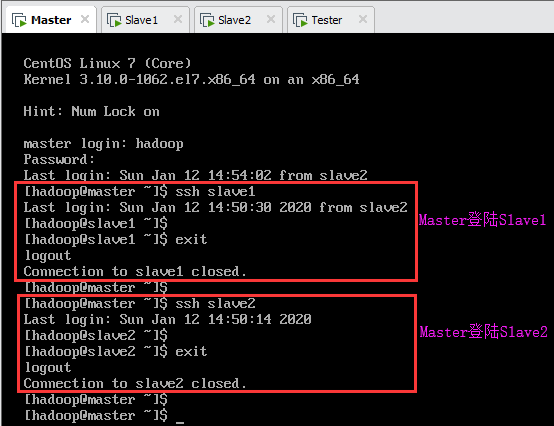
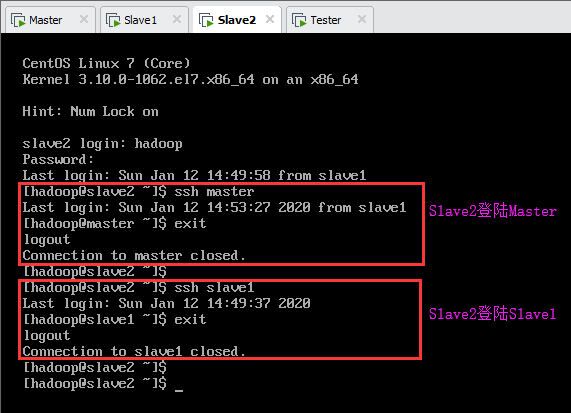
7.8.三节点互相ssh登陆测试
Master登陆Slave1及Slave2,如下图所示:
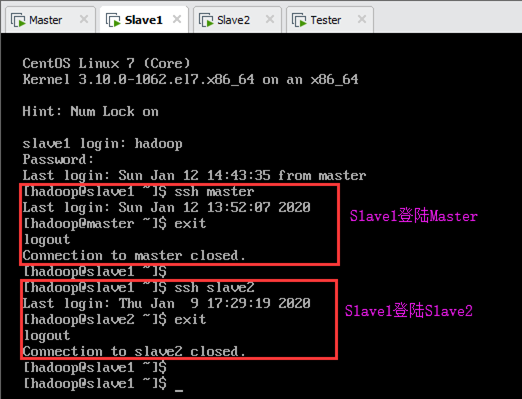
Slave1登陆Master及Slave2,如下图所示:
Slave2登陆Master及Slave1,如下图所示:
8.安装Hadoop
Hadoop安装其实就是一个将下载好的Hadoop压缩包解压到所有服务器上并进行配置的过程,推荐将Hadoop安装在各个节点服务器的相同目录下方便配置。
我们使用的Hadoop版本是hadoop-2.7.7,指定的Hadoop的安装目录(以root身份安装)是/usr/local/hadoop-2.7.7。
8.1.下载压缩包
可从官网下载压缩包,下载地址:
https://www-us.apache.org/dist/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
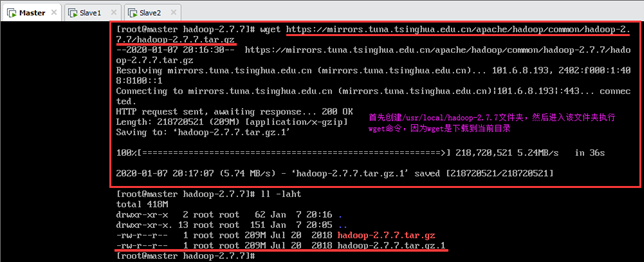
推荐从本地镜像站点下载,不仅稳定而且下载速度比较快。可从清华大学镜像站下载压缩包(耗时38s),下载地址:
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
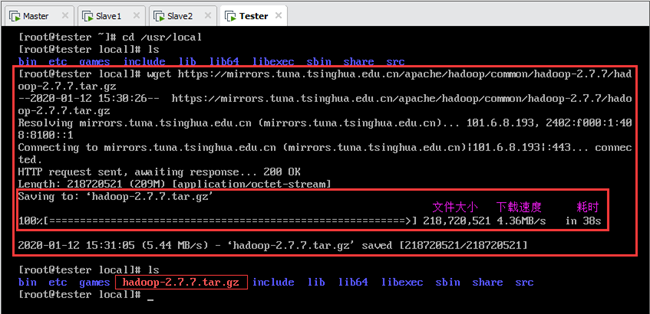
利用wget下载,必须首先安装wget(以测试机Tester为例):
注意:利用wget下载是将文件下载到当前目录,因此要先进入 /usr/local 目录,然后执行下载命令,如下图所示。
输:[root@tester local]# wget https://mirrors.tuna.tsinghua.edu.cn/apache/ hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
下载完成后,在/usr/local路径下就有了该压缩包,如下图所示。
8.2.解压Hadoop压缩包
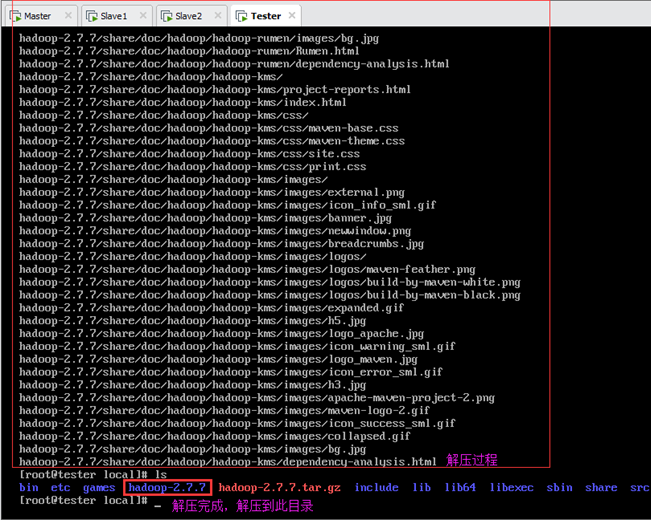
执行以下命令解压Hadoop压缩包:
等待解压完成,会在当前目录/usr/local多出一个hadoop-2.7.7文件夹,里面即为解压的内容,如下图所示。
8.3.更改用户组
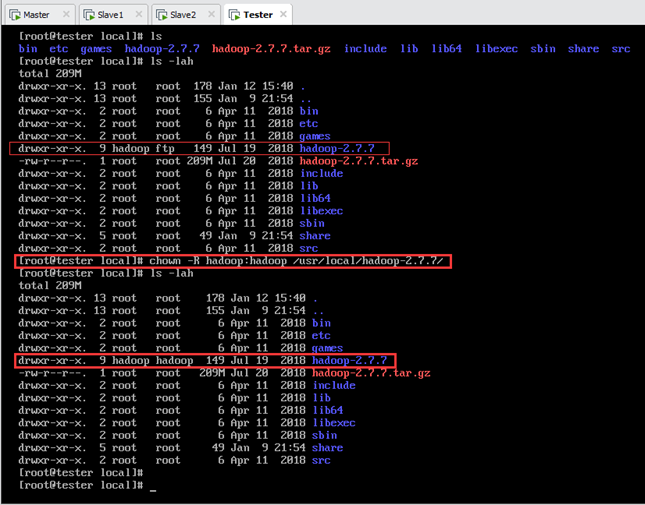
由于解压时使用的是 root 账户,所以还需要执行以下命令将Hadoop的安装目录的所有者和所属组改为 hadoop,如下图所示:
注①:在图8.3中,查看文件详细信息中的所有者和所属组,第一个root为所属用户(User),第二个root为所属组(Group)。
注②:安装Hadoop、Scala和Spark时,都是以root用户的身份安装,但在实际中操作Hadoop是以hadoop用户的身份运行的,因此在Hadoop、Scala和Spark安装完成后都需要更改用户组(后文也有说明)。
8.4.配置环境变量
编辑配置文件 /etc/profile 以配置环境变量:
在末尾处加入以下内容:
保存退出后,使之生效:
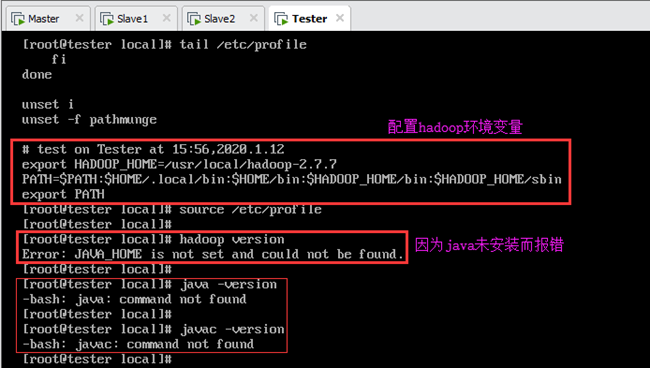
由此完成安装,查看Hadoop版本信息:
说明:由于Tester未安装java环境(见6.1),因此看不到Hadoop版本信息,输出错误信息:Error: JAVA_HOME is not set and could not be found,如图所示。
8.5.实际安装Hadoop的说明
8.5.1.安装位置的问题
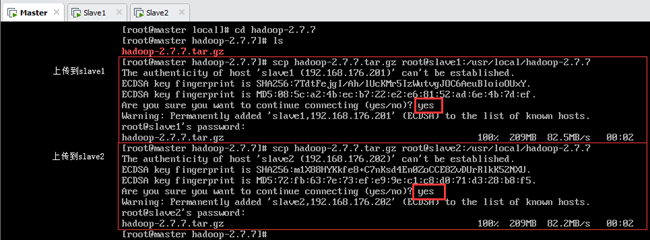
Master安装Hadoop时,在 /usr/local 目录下新建了一个文件夹 hadoop-2.7.7,使得将压缩包放到了/usr/local/hadoop-2.7.7下而不是 /usr/local,导致解压后变成了/usr/local/hadoop-2.7.7/hadoop-2.7.7,而不是/usr/local/hadoop-2.7.7,如图所示(图中应该是创建/usr/local文件夹)。
利用scp远程拷贝文件时也犯了同样的错误,都是拷贝到了/usr/local/hadoop-2.7.7下,如图所示:
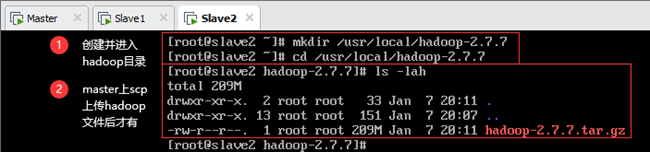
8.5.2解决安装位置的问题
对于每个节点,首先将位于/usr/local/hadoop-2.7.7下的压缩包移动到/usr/local,然后删除hadoop-2.7.7文件夹,如下图所示(截图为Slave2):
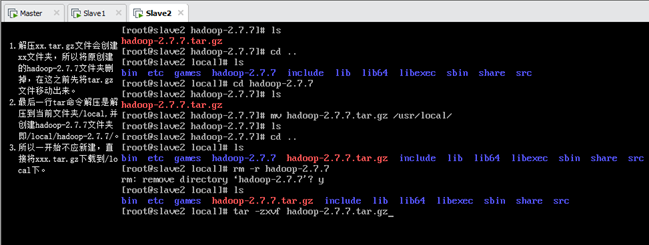
解压完成后删除压缩包,如图所示(截图为Slave2):
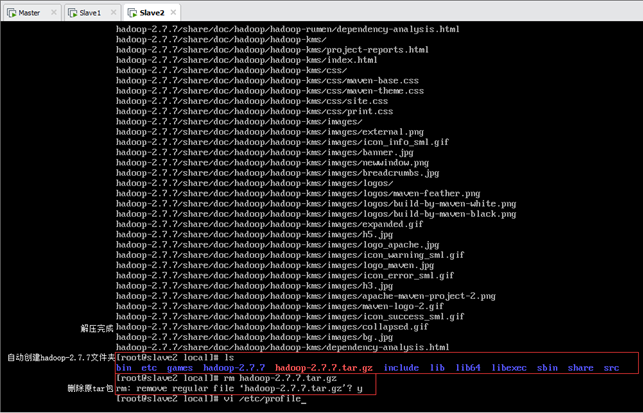
8.5.3.各个节点
①更改位置,如上8.5.2节;
②解压hadoop-2.7.7.tar.gz文件,完成后删除压缩包;
③更改用户组为hadoop;
④配置环境变量并使之生效;
⑤查看Hadoop版本。
设置完成后如图8.11~8.13所示:
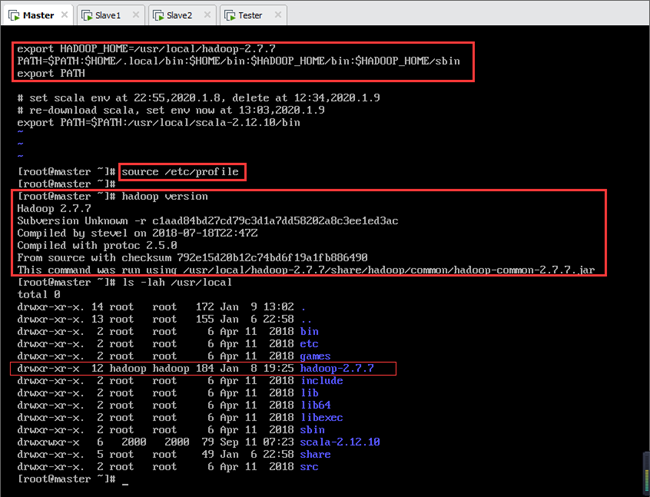
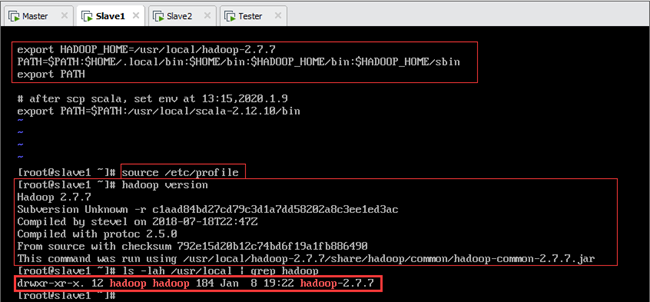
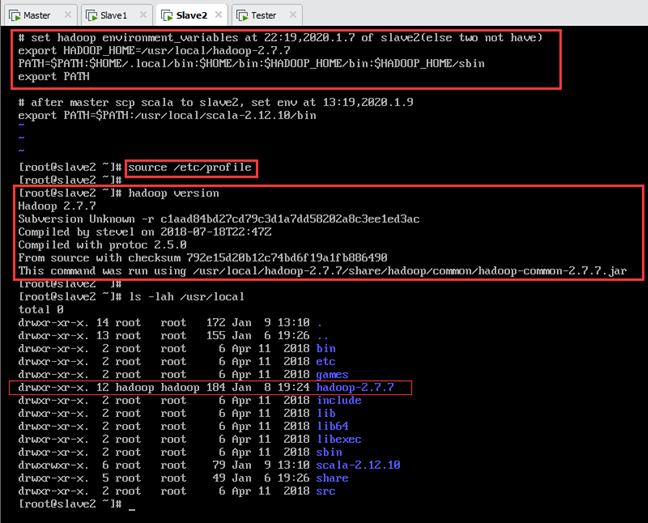
8.5.4.从节点Hadoop的安装
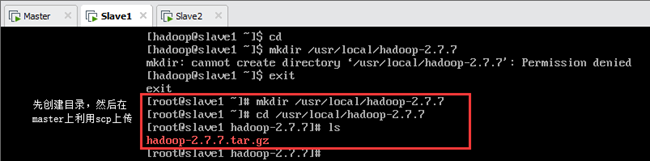
当主节点Master安装完成后,可以直接利用scp将整个/usr/local/hadoop-2.7.7文件夹传到从节点Slave1和Slave2,而不需要再次安装。
9.配置Hadoop集群
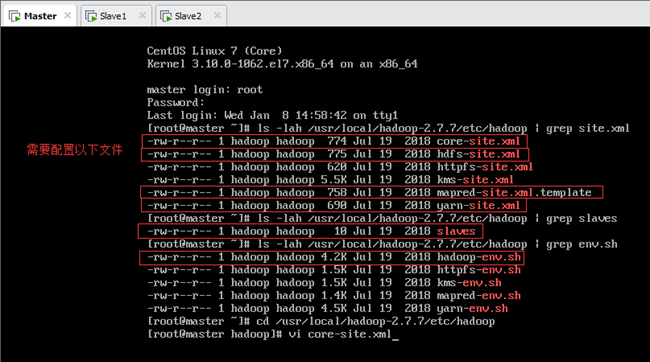
Hadoop集群的配置文件位于/usr/local/hadoop-2.7.7/etc/hadoop文件夹下,默认配置不需要修改,主要配置节点的个性配置,即①core-site.xml,②hdfs-site.xml,③mapred-site.xml.template和④yarn-site.xml四个文件,以及⑤slaves和⑥hadoop-env.sh两个文件,如下图所示。
9.1.配置core-site.xml
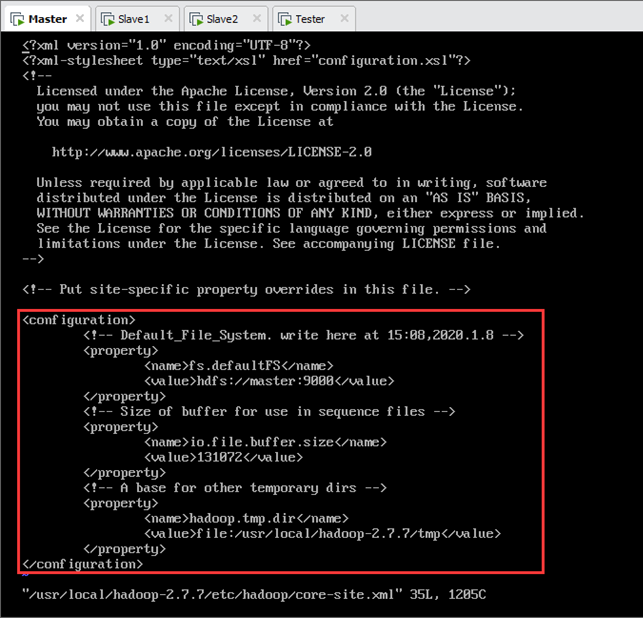
编辑Hadoop配置文件/usr/local/hadoop-2.7.7/etc/hadoop/core-site.xml,在<configuration>和</configuration>之间加入以下配置内容,如图所示(其中,按“Tab”键缩进,<!— xxx —>的内容为注释):
<!-- The name of the default file system -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- The size of buffer for use in sequence files -->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- A base for other temporary directories -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-2.7.7/tmp</value>
</property>
</configuration>
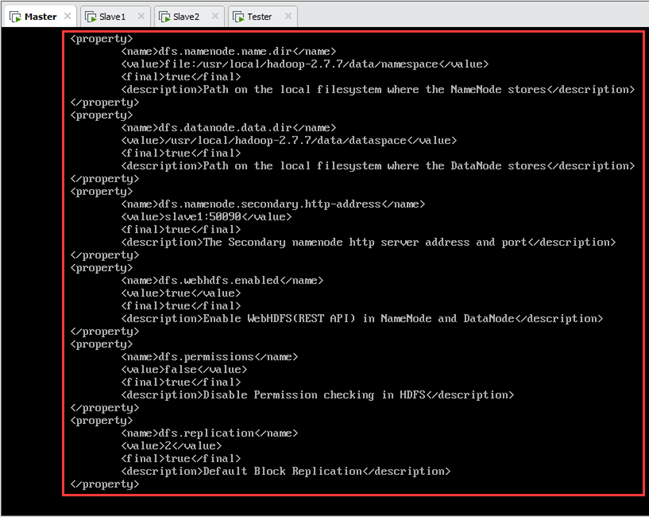
9.2.配置hdfs-site.xml
编辑/usr/local/hadoop-2.7.7/etc/hadoop/hdfs-site.xml文件,加入以下配置内容,如图9.3所示:
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-2.7.7/data/namespace</value>
<final>true</final>
<description>Path on the local filesystem where the NameNode stores</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop-2.7.7/data/dataspace</value>
<final>true</final>
<description>Path on the local filesystem where the DataNode stores Data</description>
/span> </property>
<property>
<name>dfs.namenode.secondary.http-address</name>
/span> <value>slave1:50090</value>
<final>true</final>
<description>The secondary namenode http server address and port</description>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
<final>true</final>
<description>Enable WebHDFS (REST API) in Namenodes and Datanodes</description>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<final>true</final>
<description>Disable permission checking in HDFS</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<final>true</final>
<description>Default block replication</description>
</property>
</configuration>
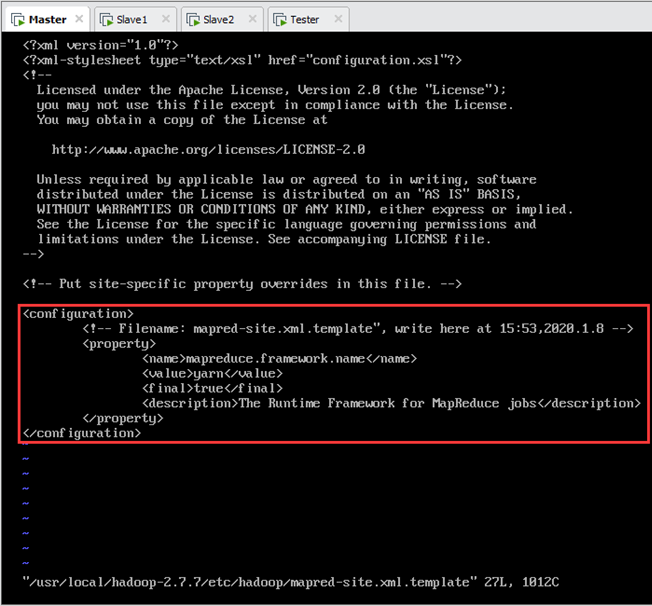
9.3.配置mapred-site.xml
编辑/usr/local/hadoop-2.7.7/etc/hadoop/mapred-site.xml.template文件,加入以下配置内容,如图9.4所示:
说明:此模板文件mapred-site.xml.template应将其重命名为mapred-site.xml。
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
<description>The runtime framework for executing MapReduce jobs</description>
</property>
</configuration>
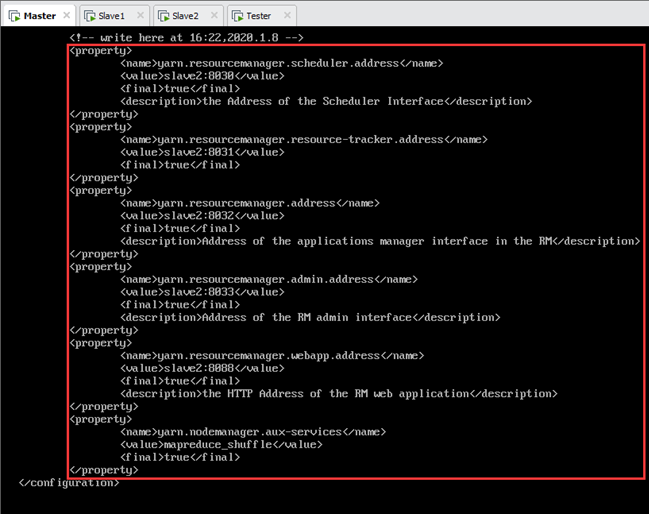
9.4.配置yarn-site.xml
编辑/usr/local/hadoop-2.7.7/etc/hadoop/yarn-site.xml文件,加入以下配置内容,如图9.5所示:
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>slave2:8030</value>
<final>true</final>
<description>The address of the scheduler interface</description>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>slave2:8031</value>
<final>true</final>
<description>The address and port of Resource Manager of YARN at Slave2</description>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>slave2:8032</value>
<final>true</final>
<description>The address of the applications manager interface in the RM</description>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>slave2:8033</value>
<final>true</final>
<description>The address of the RM admin interface</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>slave2:8088</value>
<final>true</final>
<description>The http address of the RM web application</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<final>true</final>
<description>Node Manager of YARN</description>
</property>
</configuration>
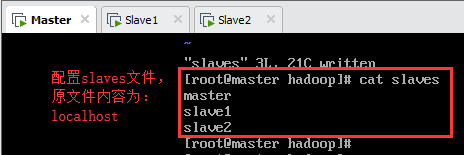
9.5.配置slaves
编辑/usr/local/hadoop-2.7.7/etc/hadoop/slaves文件,删除原有的localhost(也可以直接注释掉)加入以下内容,如下图所示:
slave1
slave2
9.6.配置hadoop-env.sh
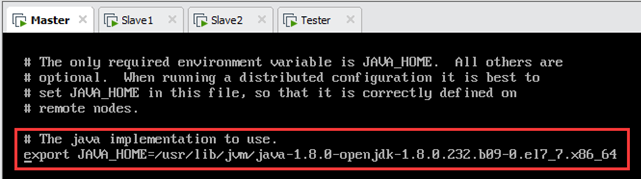
编辑/usr/local/hadoop-2.7.7/etc/hadoop/hadoop-env.sh文件,将“# The java implementation to use.”下的“export JAVA_HOME=${JAVA_HOME}”修改为:export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.232.b09-0.el7_7.x86_64。
其中,路径/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.232.b09-0.el7_7.x86_64为安装Java时设置的环境变量(见6.2.4节),如下图所示。
9.7.将配置分发到其他节点
上述9.1~9.6都是在主节点Master上配置,因此需要将其分发到Slave1和Slave2两个从节点,如图所示。
输:[root@master ~]#scp -r /usr/local/hadoop-2.7.7/etc/hadoop/* slave2:/usr/local/hadoop-2.7.7/etc/hadoop/
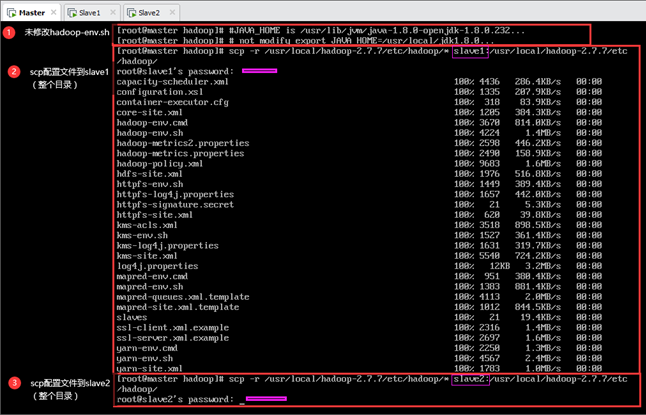
说明:上图中,尚未配置/usr/local/hadoop-2.7.7/etc/hadoop/hadoop-env.sh文件,因此scp后需要对每个节点的hadoop-env.sh文件进行配置。若先将Master上的此文件配置好,然后scp到从节点,则不需在从节点上配置该文件。
10.操作Hadoop集群
说明:以下操作Hadoop集群都是使用hadoop用户,提示符为[hadoop@master ~]$。
10.1.格式化NameNode
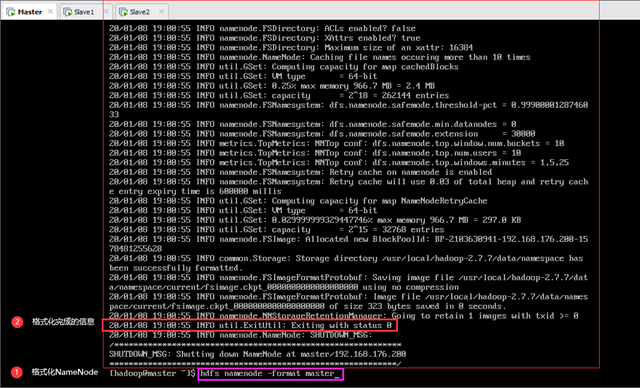
第一次启动HDFS需要先进行格式化,使用格式为“$HADOOP_PREFIX/bin/hdfs namenode -format <cluster_name>”的如下命令:
等待Master格式化完成,出现Exiting with status 0的信息即为格式化成功,如图10.1所示。
10.2.启动HDFS集群
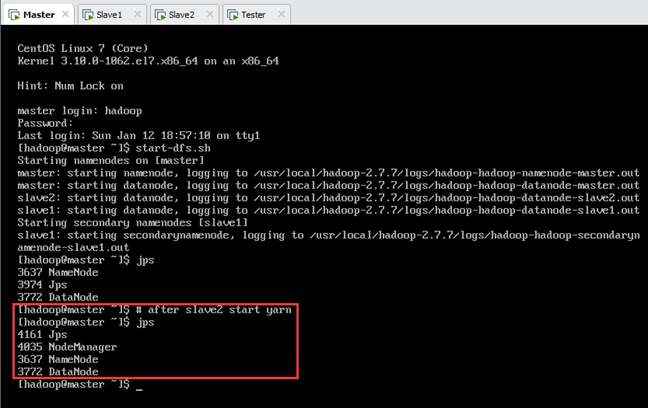
HDFS格式化完成后,使用格式为“$HADOOP_PREFIX/sbin/start-dfs.sh”的如下命令来启动HDFS集群,如图所示:
说明:使用该命令启动HDFS集群时,在集群的任意节点上执行都能够启动集群。

此时,各节点jps进程如表10.1所示,如图10.2、图10.3、图10.4所示。
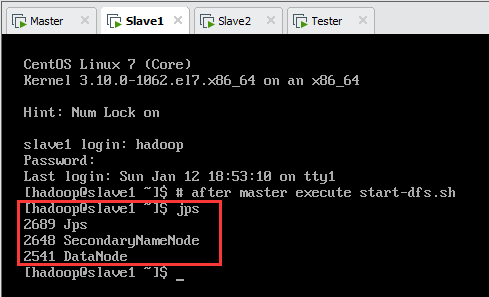
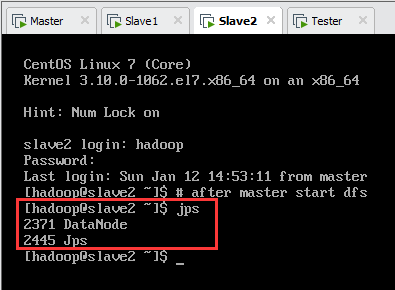
| 名称 | jps进程 |
| master | Jps,NameNode,DataNode |
| slave1 | Jps,SecondaryNameNode,DataNode |
| slave2 | Jps,DataNode |
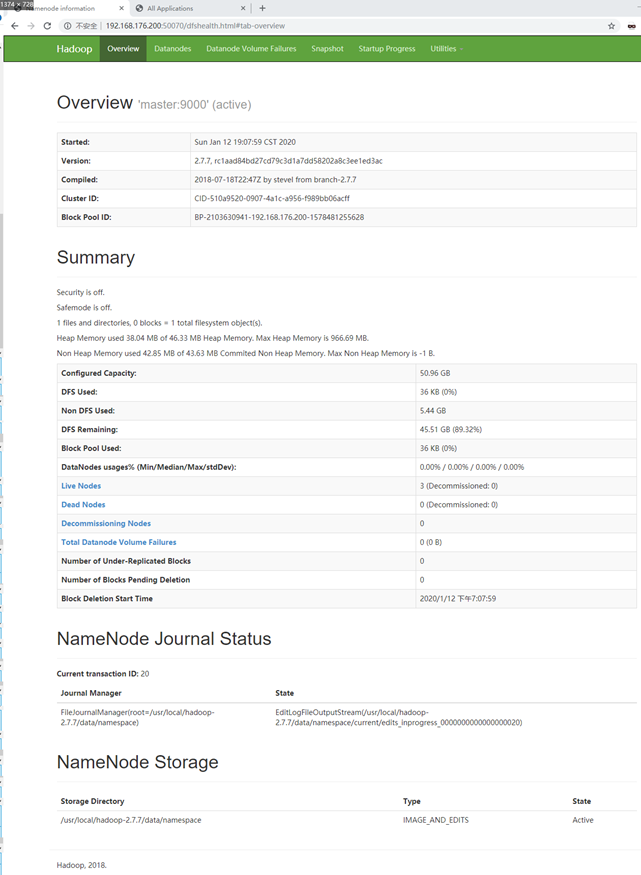
此时可在浏览器中打开http://192.168.176.200:50070查看HDFS的管理界面,如图所示。
10.3.启动YARN
启动HDFS后,使用格式为“$HADOOP_PREFIX/sbin/start-yarn.sh”的如下命令来启动YARN,如图所示:
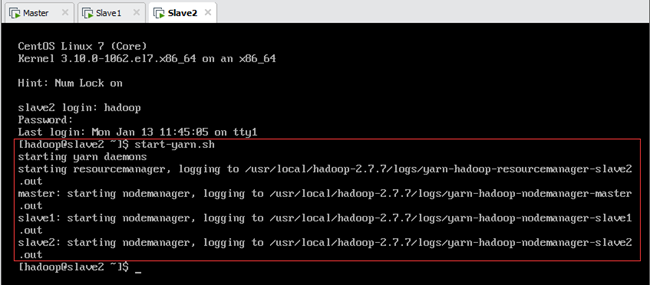
说明:在使用 start-yarn.sh 命令启动YARN集群时,必须在ResourceManager所在节点Slave2上执行该命令才能够启动 ResourceManager;当 Namenode和ResourceManger不在同一台主机时,就不能在NameNode上启动 YARN了,应该在ResouceManager所在的机器Slave2上启动YARN。
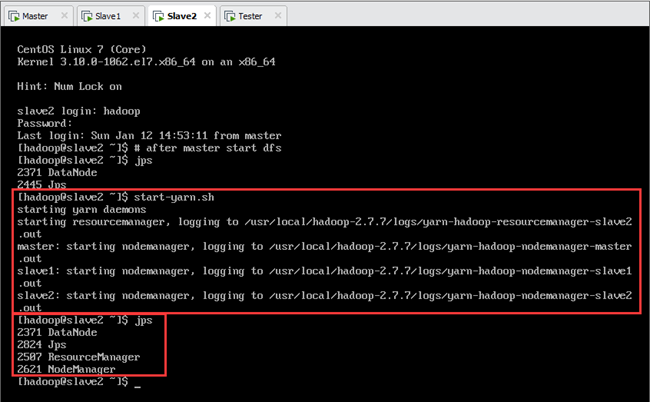
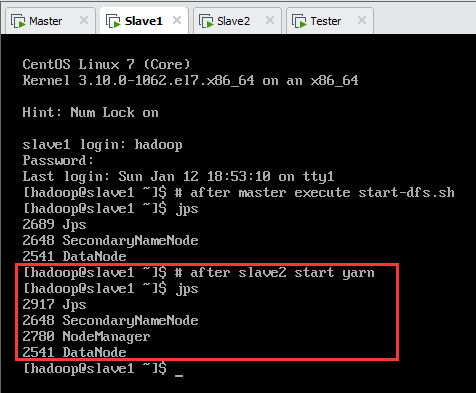
此时,各节点jps进程如表10.2所示,如图10.6、图10.7、图10.8所示。
| 名称 | jps进程 |
| master | Jps,NameNode,DataNode,NodeManager |
| slave1 | Jps,SecondaryNameNode,DataNode,NodeManager |
| slave2 | Jps,DataNode,ResourceManager,NodeManager |
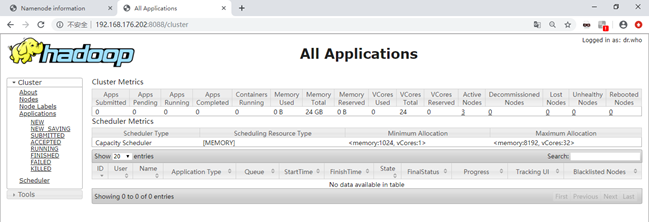
此时可在浏览器中打开http://192.168.176.202:8088查看YARN的管理界面,如图所示。
11.各节点scala安装
11.1.主节点Master上安装scala
11.1.1下载scala
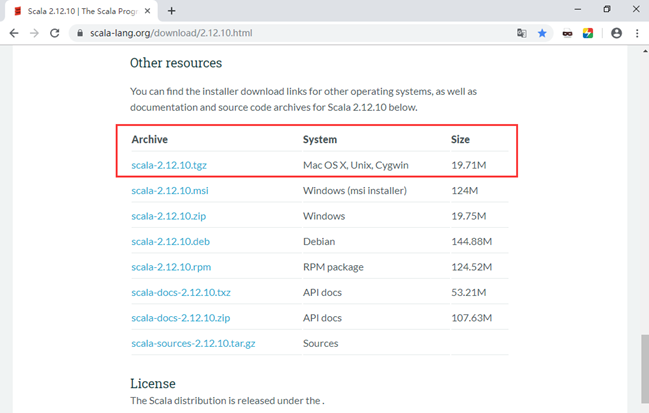
打开scala官网:http://www.scala-lang.org/download/2.12.10.html,找到对应版本,如图所示,对应的下载链接为:https://downloads.lightbend.com/scala/2.12.10/scala-2.12.10.tgz。
scala安装路径是/usr/local/scala-2.12.10。首先进入安装目录/usr/local,使用wget下载,如图所示:
输:[root@master local]# wget https://downloads.lightbend.com/scala/2.12.10/scala-2.12.10.tgz
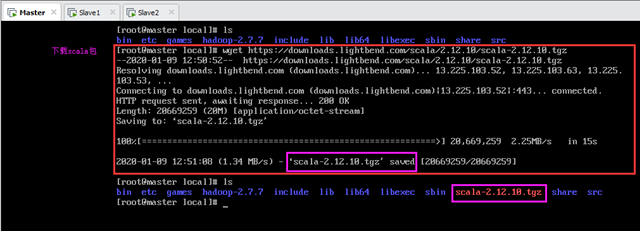
由于没有采用镜像站点资源下载,因此下载速度较慢,耐心等待下载完成。下载完成后会在当前目录生成scala文件:/usr/local/scala-2.12.10.tgz。
11.1.2解压scala压缩包
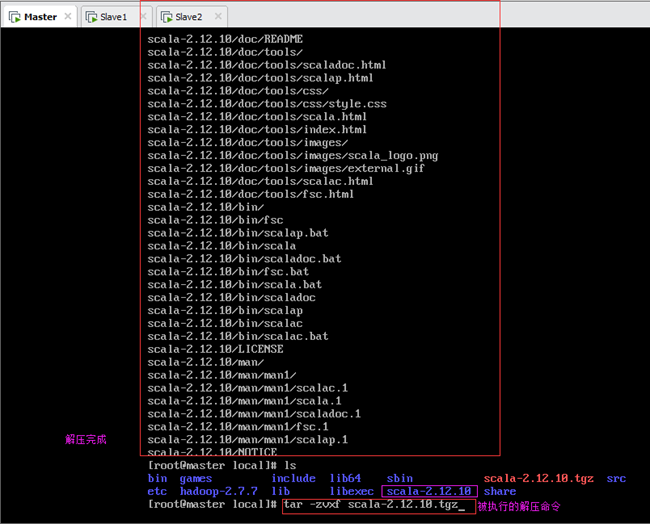
解压scala到当前文件夹,如下图11.3所示:
解压完成后,会在当前目录创建文件夹/usr/local/scala-2.12.10,scala压缩包内的所有文件都被解压到该目录。
解压完成后,删除原压缩包,执行如下命令:
说明:删除命令选项“–f”表示强制删除,删除过程中没有“是否确认删除”的提示。慎用此选项,尽量只在删除有很多子文件夹时配合“–r”(递归处理)使用。
11.1.3配置scala环境变量
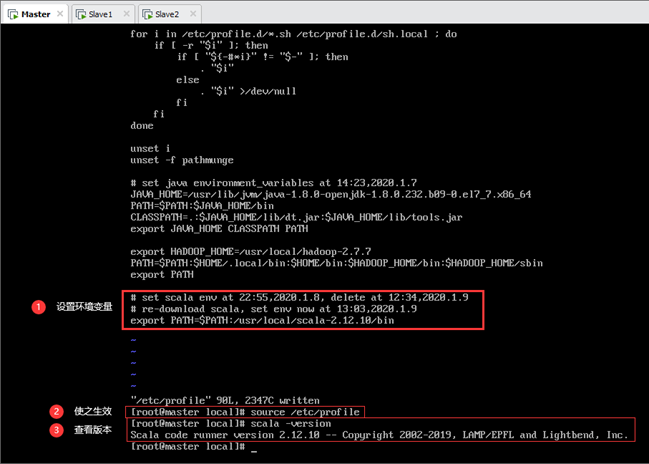
配置scala环境变量,加入export PATH=$PATH:/usr/local/scala-2.12.10/bin,如图所示:
scala环境变量配置完成后,使之生效,如图所示:
至此,Master上scala安装完成,查看scala版本,如图所示:
11.2从节点上安装scala
11.2.1.scp传输scala安装文件
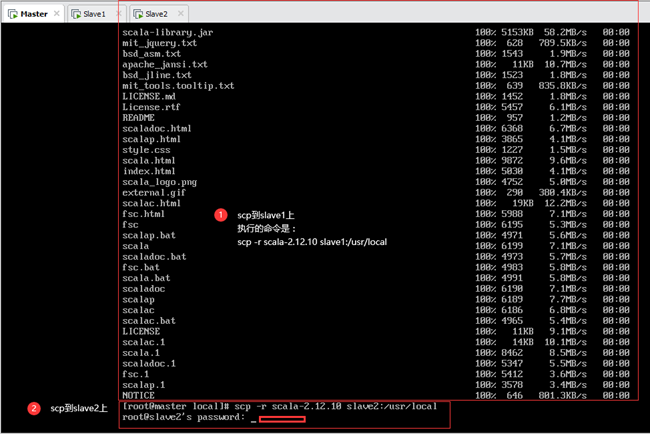
将主节点Master上安装好的scala文件夹利用scp传到从节点Slave1和Slave2上,如下图11.5所示:
输:[root@master local]# scp –r scala-2.12.10 slave2:/usr/local
注意:此处使用的是相对路径,因为当前目录为/usr/local,也可使用如下命令(绝对路径)来传输,二者没有区别:
输:[root@master local]# scp –r /usr/local/scala-2.12.10 slave2:/usr/local
11.2.2配置环境变量
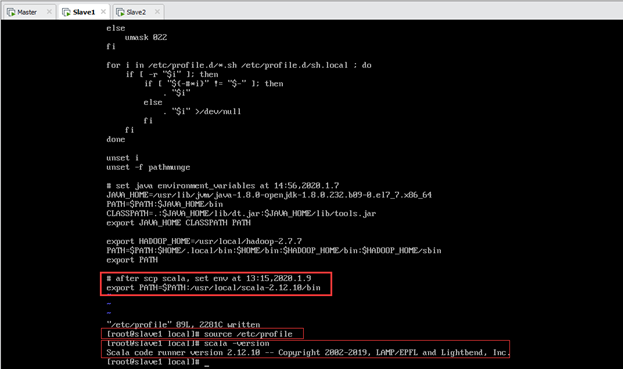
scp传输完成后,在Slave1上配置scala环境变量,步骤同11.1.3节,如图所示:
scp传输完成后,在Slave2上配置scala环境变量,步骤同11.1.3节,如图所示:
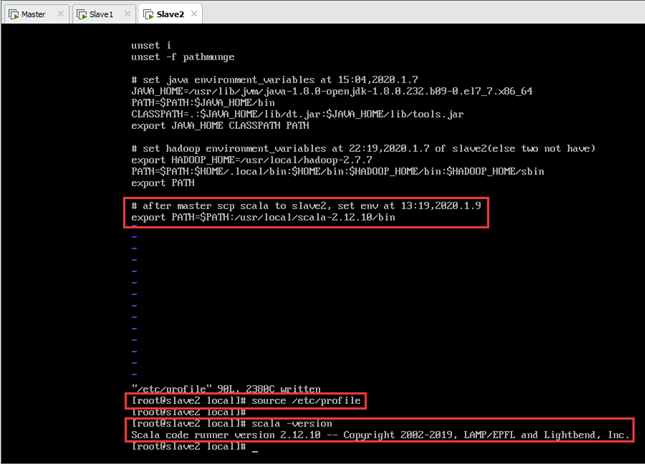
12.Spark安装及配置
12.1.主节点Master上安装spark
12.1.1下载spark压缩包
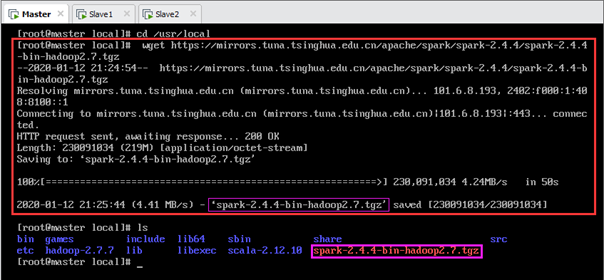
清华大学镜像站下载spark-2.4.4-bin-hadoop2.7.tgz文件,如图所示,其下载链接为:https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz。
spark的安装路径是/usr/local/ spark-2.4.4-bin-hadoop2.7。首先进入安装目录/usr/local,使用wget下载,如图所示:
输:[root@master local]# wget https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz
12.1.2.解压spark压缩包
解压spark到当前文件夹,如图所示:
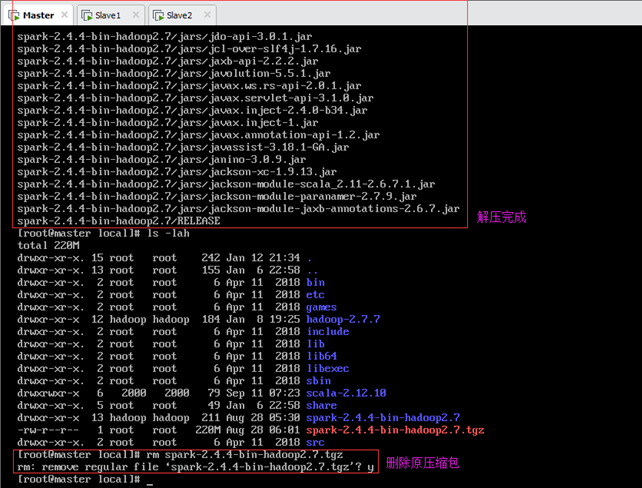
解压完成后,删除原压缩包。
12.1.3.修改spark配置文件
配置文件路径为/usr/local/spark-2.4.4-bin-hadoop2.7/conf,如图所示,并且将spark-env.sh.template重命名为spark-env.sh。

然后修改配置文件spark-env.sh,如图12.4所示。
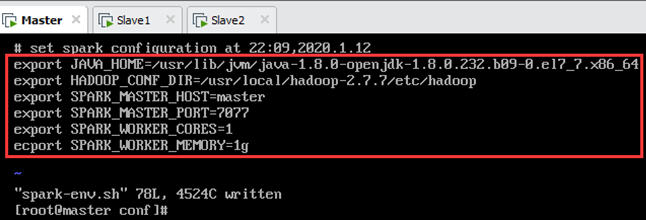
在末尾加上如下红色字体内容(其中JAVA_HOME应与java安装时的配置保持一致,黑色字体为注释),如图12.4所示:
# 配置JAVA_HOME应与java安装时的配置保持一致,见6.2.4节
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.232.b09-0.el7_7.x86_64
# 一般来说,spark任务有很大可能性需要去HDFS上读取文件,所以配置上
# 如果说你的spark就读取本地文件,也不需要yarn管理,则不用配
export HADOOP_CONF_DIR=/usr/local/hadoop-2.7.7/etc/hadoop
# 设置Master的主机名
export SPARK_MASTER_HOST=master
# 提交Application的端口,默认就是这个,万一要改就改这里
export SPARK_MASTER_PORT=7077
# 每一个Worker最多可以使用的cpu core的个数,我虚拟机就一个...
# 真实服务器如果有32个,你可以设置为32个
export SPARK_WORKER_CORES=1
# 每一个Worker最多可以使用的内存,虚拟机设置的是2G
# 真实服务器如果有128G,你可以设置为100G
export SPARK_WORKER_MEMORY=1g
12.1.4.修改slaves文件
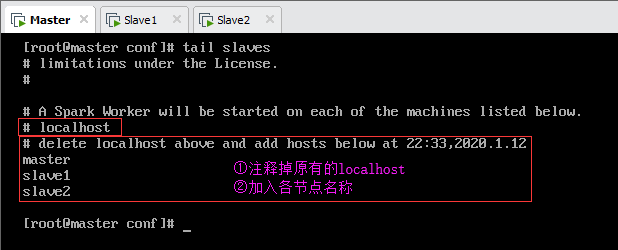
如图12.3,首先将slaves.template重命名为slaves,然后修改slaves文件,删除或注释掉“localhost”,加入三台节点的主机名,如图所示。
12.1.5.配置spark环境变量
配置spark环境变量:
加入如下内容:
export PATH=\$PATH:\$SPARK_HOME/bin:\$SPARK_HOME/sbin
spark环境变量配置完成后,使之生效,如图12.6所示:
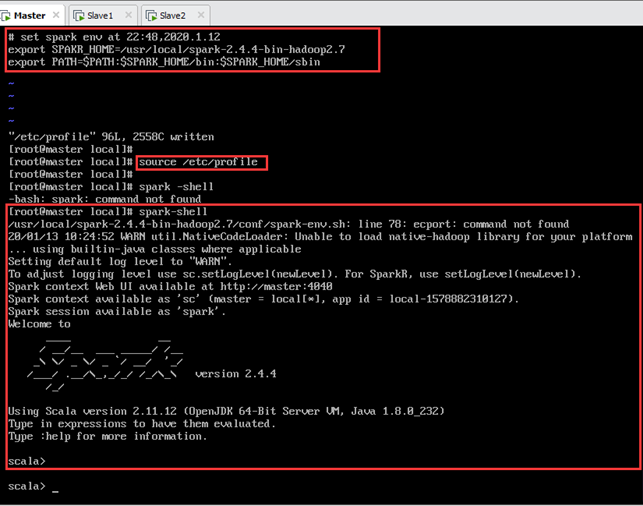
输入以下命令启动Spark,如图12.6所示:
12.2.从节点上安装spark
12.2.1.scp传输spark安装文件
将主节点Master上安装好的spark利用scp传到从节点Slave1和Slave2上,如图所示:
输:[root@master local]# scp –r spark-2.4.4-bin-hadoop2.7 slave2:/usr/local
注意:此处使用的是相对路径,因为当前目录为/usr/local,也可使用绝对路径。
12.2.2.配置spark环境变量
(1)Slave1节点配置spark环境变量
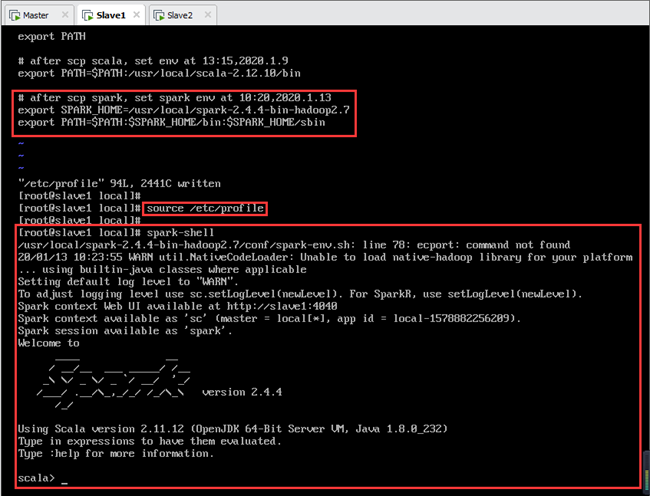
scp传输完成后,在Slave1上配置spark环境变量,步骤同12.1.5节。
Slave1节点上spark环境变量配置完成后,输入以下命令启动Spark,如图所示:
(2)Slave2节点配置spark环境变量
scp传输完成后,在Slave2上配置spark环境变量,步骤同12.1.5节。
Slave2节点上spark环境变量配置完成后,输入以下命令启动Spark,如图12.9所示:
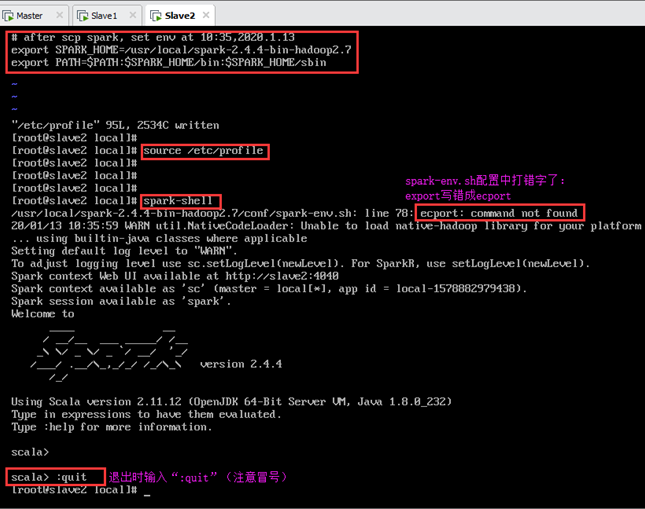
说明:退出scala时需输入“:quit”,上图是spark-shell下的命令行,界面与scala下的命令行不同,如图所示。
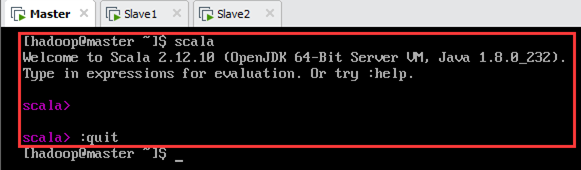
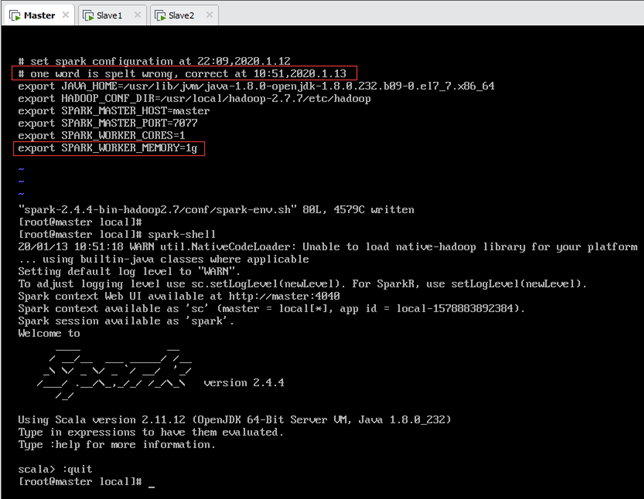
12.3.修改spark-env.sh
在每个节点上改正spark-env.sh的错误(如图12.4),将最后一行“ecport”修改为“export”。
配置文件路径为/usr/local/spark-2.4.4-bin-hadoop2.7/conf/spark-env.sh,如下图所示。
13.启动Spark集群
参考:https://www.cnblogs.com/ZJdiem/p/11664634.html
13.1.说明
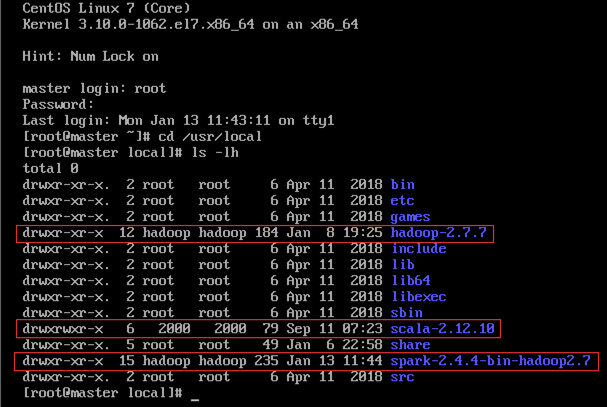
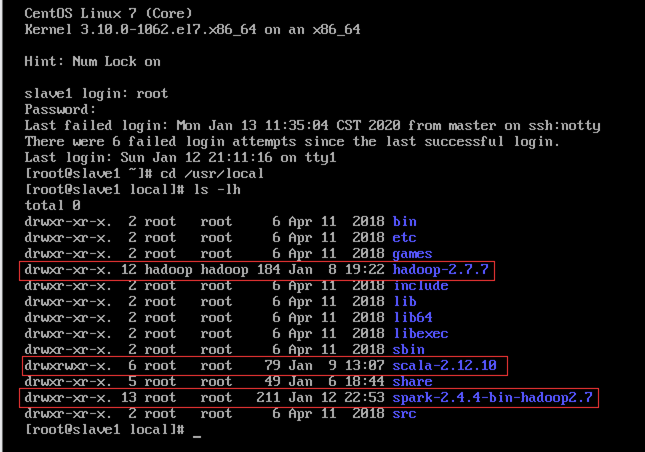
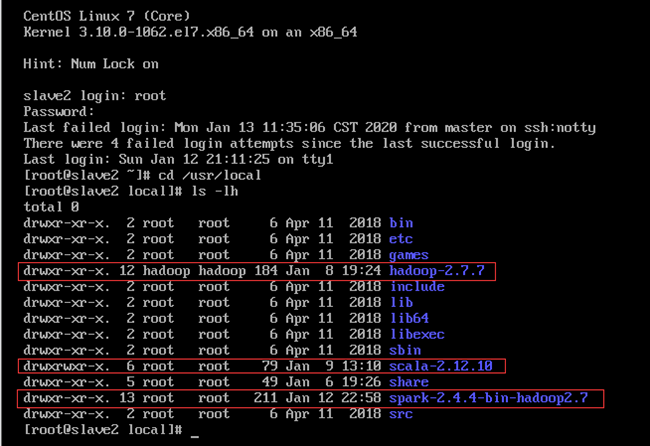
Hadoop、Scala和Spark都是安装在/usr/local文件夹下,如图13.1~13.3所示。
由于安装时是以root身份安装的,但操作Hadoop相关的东西时是以hadoop用户,因此会产生权限的问题,所以需要登陆root账号,更改用户组为hadoop用户,见8.3节。
从图中可以看到,Hadoop的所有者和用户组正常(因为安装Hadoop时已经修改过),而Scala和Spark的所有者和用户组则不对,后文修改。
13.2.更改Scala和Spark的用户组
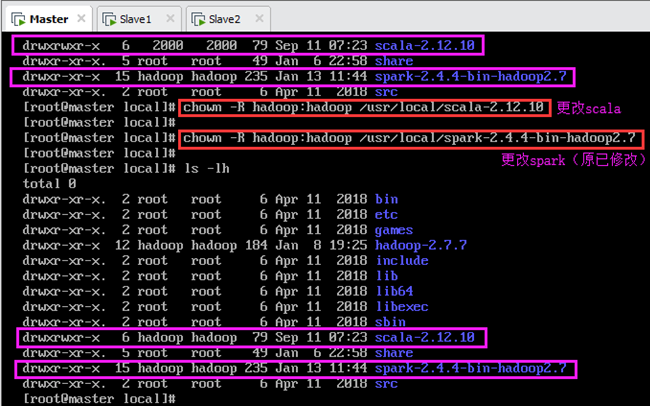
13.2.1.主节点Master
在Master上执行以下命令将Scala和Spark的安装目录的所有者和所属组改为hadoop用户,如图13.4所示:
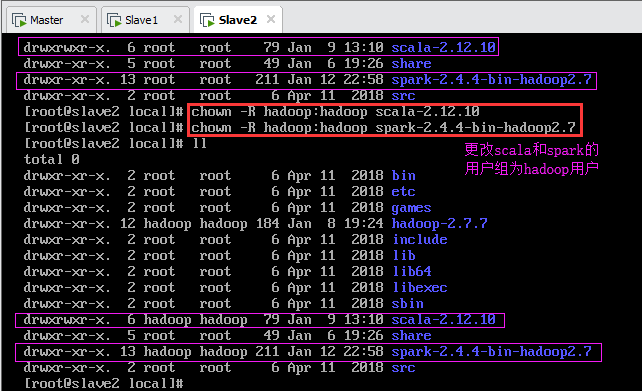
输:[root@master local]# chown -R hadoop:hadoop /usr/local/spark-2.4.4-bin-hadoop2.7
说明:由于前面安装Spark时已经更改过,因此只需要更改Scala安装目录的所有者和所属组,如图13.4所示。由图可知,修改前,scala的用户组为2000、spark的用户组为hadoop;修改后,scala的用户组为hadoop、spark的用户组为hadoop。
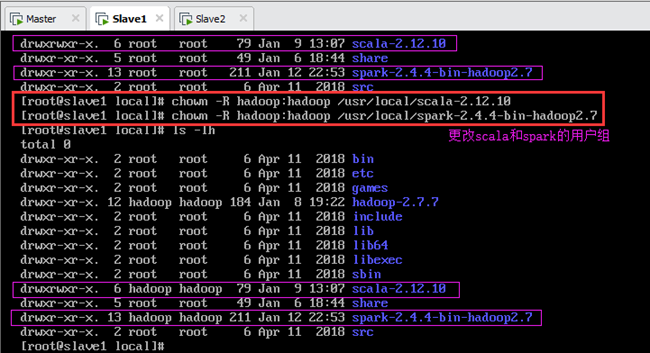
13.2.2.从节点Slave1
在Slave1上执行以下命令将Scala和Spark的安装目录的所有者和所属组改为hadoop用户,如图13.5所示:
输:[root@slave1 local]# chown -R hadoop:hadoop /usr/local/spark-2.4.4-bin-hadoop2.7
由图可知,修改前,scala和spark的用户组均为root;修改后,scala和spark的用户组为hadoop。
13.2.3.从节点Slave2
在Slave2上执行以下命令(此处使用的是相对路径)将Scala和Spark的安装目录的所有者和所属组改为hadoop用户,如图13.6所示:
输:[root@slave2 local]# chown -R hadoop:hadoop spark-2.4.4-bin-hadoop2.7
由图可知,修改前,scala和spark的用户组均为root;修改后,scala和spark的用户组为hadoop。
13.3.启动Hadoop集群
注意:启动Spark集群之前必须先启动Hadoop集群。
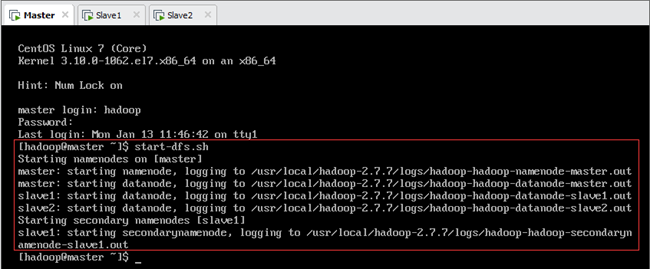
首先以hadoop用户身份登陆,然后在主节点Master上运行start-dfs.sh启动HDFS集群(此时各节点jps进程如表13.1所示),最后在从节点Slave2上运行start-yarn.sh启动YARN集群(此时各节点jps进程如表13.1所示),如图所示。
13.4.启动Spark集群
注意:启动Spark集群之前必须先启动Hadoop集群。
Hadoop集群启动后,首先在Master节点进入spark目录,然后启动Spark集群,如图:
输:[hadoop@master spark-2.4.4-bin-hadoop2.7]$sbin/start-master.sh
输:[hadoop@master spark-2.4.4-bin-hadoop2.7]$sbin/start-slaves.sh
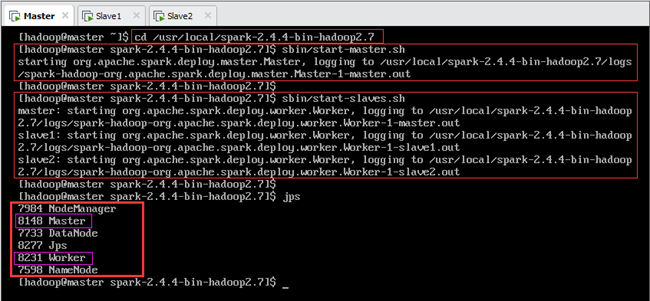
至此,Spark集群启动完成,此时主节点Master上jps进程如图13.9所示,从节点Slave1和Slave2上jps进程如图13.10所示,各节点集群启动前后jps进程如表13.1所示。
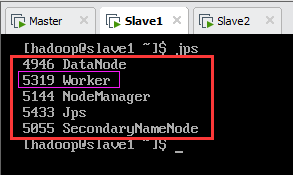

| 节点名称 | Master启动HDFS | Slave2启动YARN | Master启动Spark |
| master | Jps,NameNode,DataNode | Jps,NameNode,DataNode NodeManager | Jps,NameNode,DataNode NodeManager Master,Worker |
| slave1 | Jps,SecondaryNameNode,DataNode | Jps,SecondaryNameNode,DataNode NodeManager | Jps,SecondaryNameNode,DataNode NodeManager Worker |
| slave2 | Jps,DataNode | Jps,DataNode ResourceManager,NodeManager | Jps,DataNode ResourceManager,NodeManager Worker |
注:表中不同颜色代表启动不同集群后增加的jps进程,其中绿色为Master启动HDFS集群后增加的进程,洋红为Slave2启动YARN集群后增加的进程,绿色为Master启动Spark集群后增加的进程;单元格内容为启动不同集群后各节点所有的jps进程。
此时可在浏览器中打开http://192.168.176.200:8080,查看Spark集群的管理界面,如下图13.11所示。
同时,HDFS的管理界面为http://192.168.176.200:50070,见10.2节图10.5;YARN的管理界面为http://192.168.176.202:8088,见10.3节图10.9。
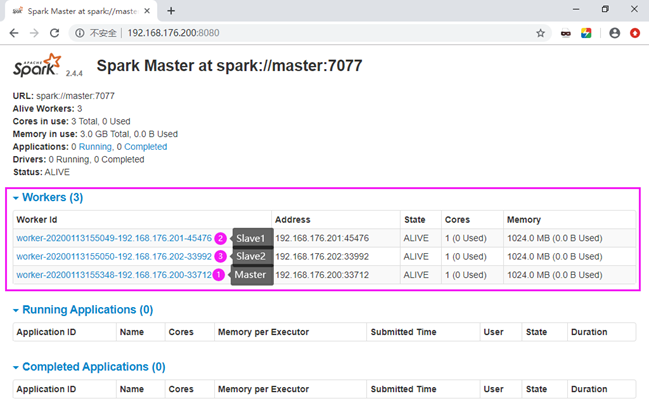
至此,集群搭建完毕。